Featured Articles
Recent tech articles that we loved...
Bowen Deng | Machine Learning Engineer, Homefeed Candidate Generation; Zhibo Fan | Machine Learning Engineer, Homefeed Candidate Generation; Dafang He | Machine Learning Engineer, Homefeed Relevance; Ying Huang | Machine Learning Engineer, Curation; Raymond Hsu | Engineering Manager, Homefeed CG Product Enablement; James Li | Engineering Manager, Homefeed Candidate Generation; Dylan Wang | Director, Homefeed Relevance; Jay Adams | Principal Engineer, Pinner Curation & Growth
Introduction
At Pinterest, our mission is to bring everyone the inspiration to create a life they love. Finding the right content online and serving the right audience plays a key role in this mission. Modern large-scale recommendation systems usually include multiple stages where retrieval aims at retrieving candidates from billions of candidate pools, and ranking predicts which item a user tends to engage from the trimmed candidate set retrieved from early stages [2]. Fig 1 illustrates a general multi-stage recommendation funnel design in Pinterest.
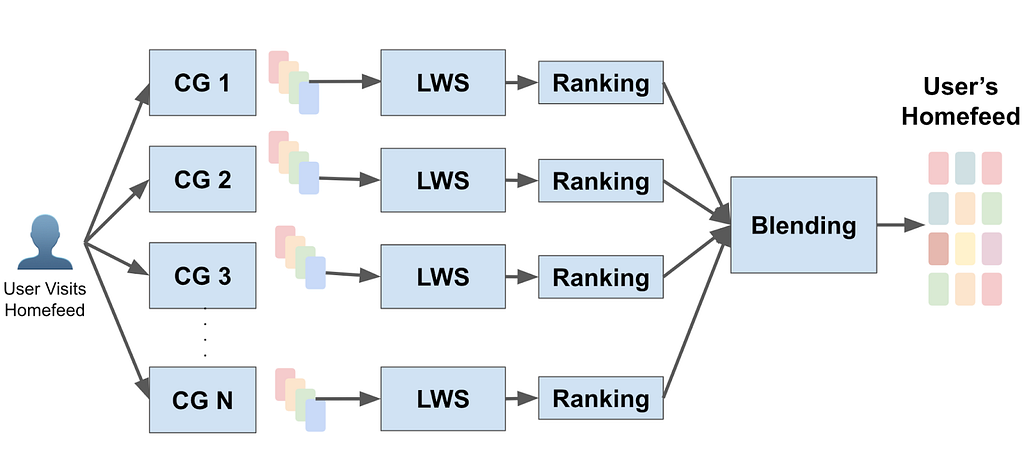
The Pinterest ranking model is a powerful transformer based model learned from a raw user engagement sequence with a mixed device serving [3]. It is powerful at capturing users’ long and short term engagement and gives instant predictions. However, Pinterest’s retrieval system in the past differs, as many of them are based on heuristic approaches such as those based on Pin-Board graphs or user-followed interests. This work illustrates our effort in successfully building Pinterest an internal embedding-based retrieval system for organic content learned purely from logged user engagement events and serves in production. We have deployed our system for homefeed as well as notification.
Methods
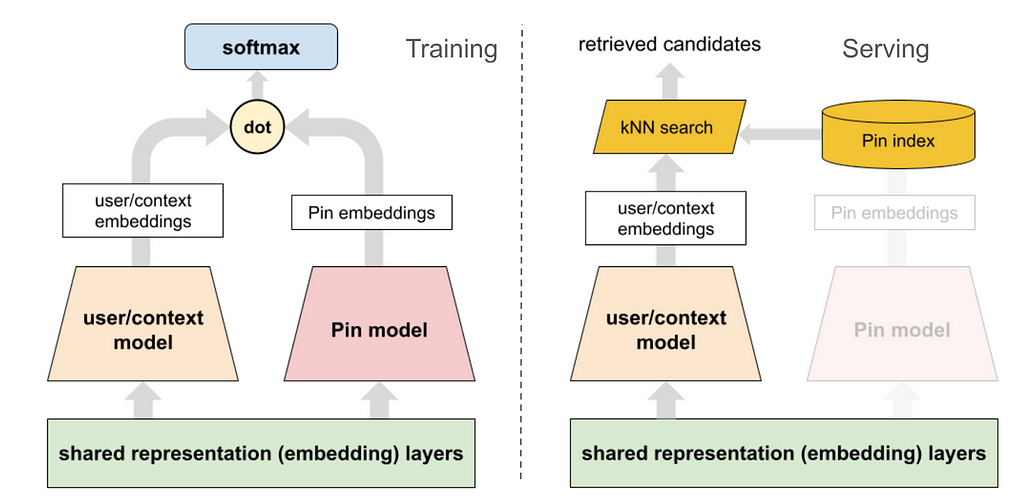
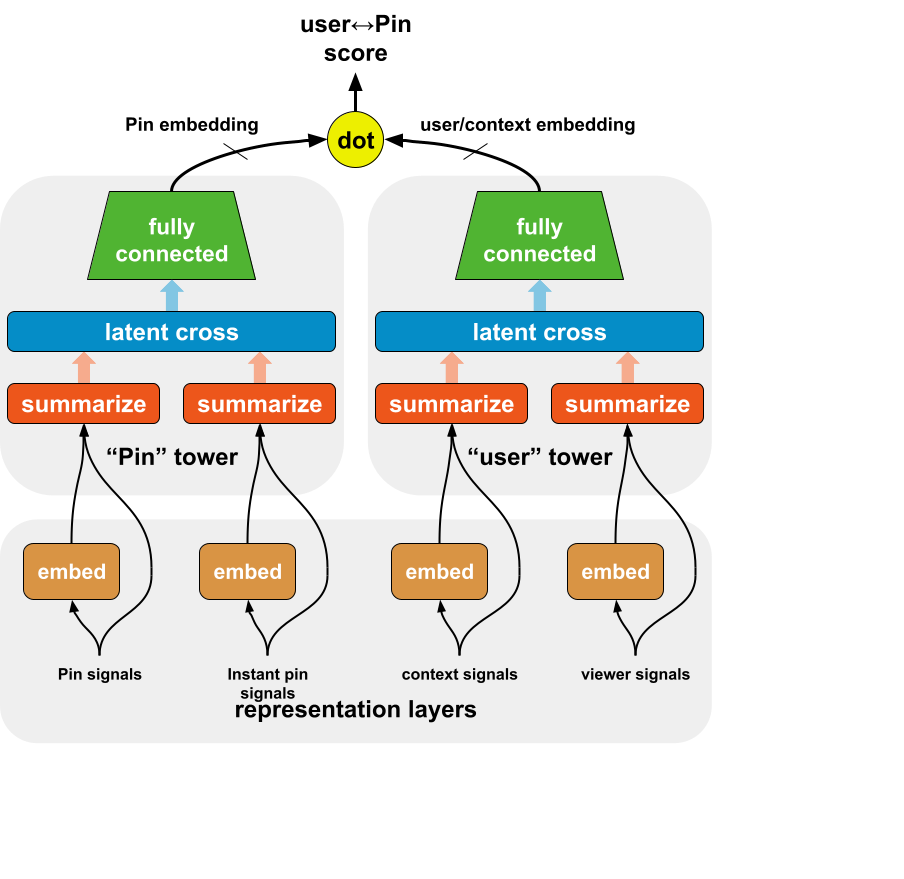
A two tower-based approach has been widely adopted in industry [6], where one tower learns the query embedding and one tower learns the item embedding. The online serving will be cheap with nearest neighbor search with query embedding and item embeddings. This section illustrates the current machine learning design of the two-tower machine learning model for learned retrieval at Pinterest.
The general two-tower model architecture with training objective and serving illustration is in diagram Fig 2.
For training an efficient retrieval model, many works model it as an extreme multi-class classification problem. While in practice we can not do softmax over all item corpus, we can easily leverage in batch negative, which provides a memory efficient way of sampling negative. To put it more formally, a retrieval model should optimize where C is the entire corpus and T is all true labels.
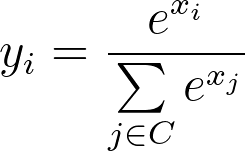
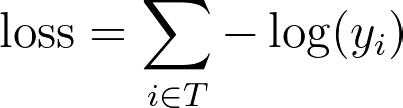
However, in practice we can only sample softmax over a set of negative items S.
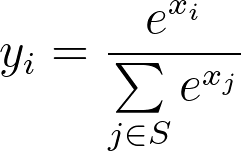
Where given a sampled set D, and the sampled softmax could be formulated as:
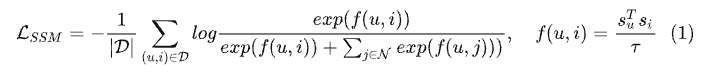
As we sample items from our training set that might have popularity bias, it is important for us to correct the sample probability [1]. We use simple logic tuning based on the estimated probability for each item.
𝐿⟮user, item⟯ = 𝒆user · 𝒆item - log P⟮item is in the batch⟯
Where 𝒆user , 𝒆item are the user embedding and item embedding correspondingly.
In our model design, we encode user long-term engagement [11] , user profile, and context as input [2] in the user tower (as shown later in Fig 4).
System Designs
As Pinterest serves over 500 million MAUs, designing and implementing an ANN-based retrieval system is not trivial. At Pinterest, we have our in-house ANN serving system designed based on algorithms [5, 7]. In order to be able to serve the item embeddings online, we break it down into two pieces: online serving and offline indexing. In online serving, user embedding is computed during request time so it can leverage the most up-to-date features to do personalized retrieval. In offline indexing, millions of item embeddings are computed and pushed to our in-house Manas serving system for online serving. Fig. 4 illustrates the system architecture for embedding-based retrieval with auto retraining adopted.
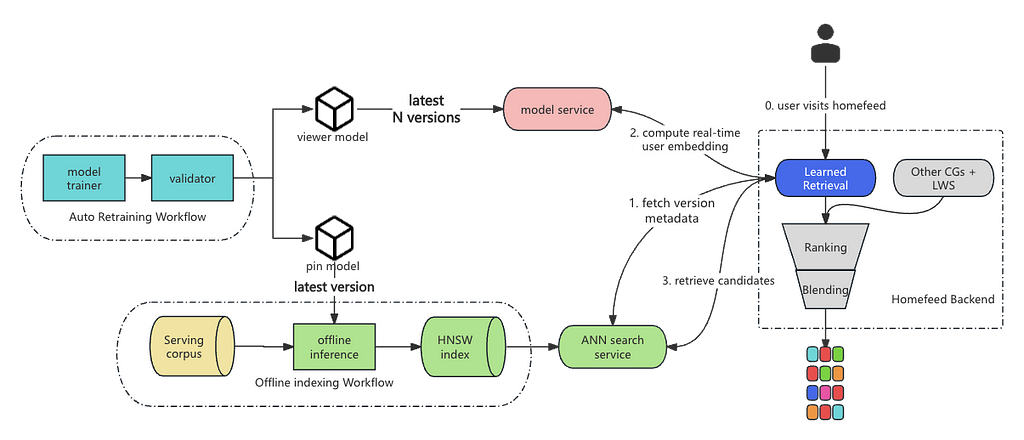
Auto Retraining
In a real-world recommendation system, it’s a necessity to frequently retrain the models to refresh the learned knowledge of users and capture recent trends. We established an auto retraining workflow to retrain the models periodically and validate the model performance before deploying them to the model and indexing services.
However, different from ranking models, two-tower models are split into two model artifacts and deployed to separate services. When a new model is retrained, we need to ensure that the serving model version is synchronized between the two services. If we do not consider version synchronization, due to the difference in deployment speed (where usually the Pin indexing pipeline takes much longer time than the viewer model being ready), candidate quality will drastically drop if the embedding space is mismatched. From the infrastructure perspective, any rollback on either service will be detrimental. Moreover, when a new index is built and being rolled out to production, the hosts of ANN search service will not change altogether immediately; this ensures that during the rollout period, a certain percentage of the traffic won’t suffer from model version mismatch.
To tackle the problem, we attach a piece of model version metadata to each ANN search service host, which contains a mapping from model name to the latest model version. The metadata is generated together with the index. At serving time, homefeed backend will first get the version metadata from its assigned ANN service host and use the model of the corresponding version to get the user embeddings. This ensures “anytime” model version synchronization: even if some ANN hosts have model versions N and others have versions N+1 during the index rollout period, the model version is still synchronized. In addition, to ensure rollback capability, we keep the latest N versions of the viewer model so that we can still compute the user embeddings from the right model even if the ANN service is rolled back to its last build.
Experiment and Results
Homefeed in Pinterest is probably the most complicated system that needs to retrieve items for different cases: Pinner engagement, content exploration, interest diversification, etc. It has over 20 candidate generators served in production with different retrieval strategies. Currently the learned retrieval candidate generator aims for driving user engagement. It has the top user coverage and top three save rates. Since launched, it has helped deprecate two other candidate generators with huge overall site engagement wins.
Conclusion and Future Works
In this blog, we presented our work in building our learned retrieval system across different surfaces in Pinterest. The machine learning based approach enables us for fast feature iteration and further consolidates our system.
Acknowledgement
We would like to thank all of our collaborators across Pinterest. Zhaohui Wu, Yuxiang Wang, Tingting Zhu, Andrew Zhai, Chantat Eksombatchai, Haoyu Chen, Nikil Pancha, Xinyuan Gui, Hedi Xia, Jianjun Hu, Daniel Liu, Shenglan Huang, Dhruvil Badani, Liang Zhang, Weiran Li, Haibin Xie, Yaonan Huang, Keyi Chen, Tim Koh, Tang Li, Jian Wang, Zheng Liu, Chen Yang, Laksh Bhasin, Xiao Yang, Anna Kiyantseva, Jiacheng Hong.
References:
[1] On the Effectiveness of Sampled Softmax Loss for Item Recommendation
[2] Deep Neural Networks for YouTube Recommendations
[3] Transact: Transformer-based realtime user action model for recommendation at pinterest
[4] Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time
[5] Manas HNSW Streaming Filters
[6] Pinterest Home Feed Unified Lightweight Scoring: A Two-tower Approach
[8] Sample Selection Bias Correction Theory
[9] PinnerFormer: Sequence Modeling for User Representation at Pinterest
Establishing a Large Scale Learned Retrieval System at Pinterest was originally published in Pinterest Engineering Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.

Code Mash takes place in Sandusky Ohio and brings thought leaders from across the US and the world to the Midwest to talk about the latest trends and best practices in the tech world. It also serves as a fantastic way to distract yourself from the snow and cold surrounding the conference. The four-day conference is a grueling but exciting experience.
https://medium.com/media/2f6904cffd0a5fdb91bcc9b2da4d0114/hrefThe Pre-compiler
The first two days, dubbed “pre-compiler”, feature in-depth hands-on workshops. These are four-hour sessions that allow for more in-depth exploration of a topic.
Hands-On Threat Modeling Workshop
Presented by: Robert Hurlbut
My first session was all about threat modeling, what it is, why it’s important, who should do it, and when should it happen. This session used a fictional company and ecommerce site as a basis walking through the process and making a threat model. The threat modeling process can be summarized into four steps.
1. What are we working on?
2. What could go wrong?
3. What are we going to do about it?
4. Did we do a good enough job?
For a threat model, documenting the system is making a series of diagrams such as a data flow diagram to describe how the system works. Since everything is based on diagrams, it’s possible to do threat modeling before a system is even implemented. To Identify threats there are many published methodologies focusing on various areas such as common attack surfaces, previous successful attack patterns, and industry best practices. We used STRIDE as a basis to organize and classify threats in the workshop, which is a more general approach that was one of the first proposed methods.
- Spoofing
- Tampering
- Repudiation
- Information Disclosure
- Denial of Service
- Elevation of Privilege
After identifying threats, decisions need to be made on what should be mitigated, removed, outsourced, or maybe even accepted as a risk.
The session concluded with an overview of available threat modeling tools that can help identify and track threats from provided models, and advice on how to bring threat modeling into your development process, or where to start if you have a massive system with no models.
Enterprise Grade Micro Frontends
Presented By: Mark Thompson and David Nicholas
This session was an introduction to what micro front ends are, and a workshop implementing a micro frontend from existing components. This session gave an overview of the various approaches to do a micro frontend, but the workshop was based on the client-side Module Federation approach.
Module federation uses the key terms of Remote and Host. A Remote is exposed code that can be consumed somewhere at run time. A Host Is what consumes a Remote or Remotes. A project using Module Federation is composed of a shell application that Hosts various Remotes made by potentially separate teams. This is all tied together at runtime through a series of configurations.
Unlock the Power of Messaging Patterns
Presented by: Chad Green
This session was all about messaging systems and how they work at a tech agnostic level to provide reliable and scalable communication while enabling decoupled components. This session started with the foundational basics of Publish/Subscribe messaging and continued to build on that base concept to enable more functionality. Then using processing patterns like filtering, aggregating, or scatter-gather to provide other ways to consume messages than a 1:1 produce consume scenario. To ensure robustness and fault tolerance into a system dead letter queues and circuit breaker patterns are useful approaches. Other patterns like Claim checks can be used to share large data without putting it in messages. Transactional queues and the Saga pattern are useful for ensuring data consistency and managing longer processes. This was a great exposure to the basics of messaging and a strong explanation of why it should be used within systems and the value it can bring.
Using Test Doubles to Improve Your Developer Confidence
Presented By: Jeffry Gonzalez
This session covered ways to help isolate the code you are working on to better test it without external dependencies. Mock Service Workers is a JavaScript library that allows you to write a mock backend in JavaScript while developing a web UI. This appears to be a great tool to isolate a UI for both testing or doing a UI first development. When writing the mock service workers, you are essentially defining the contract needed for the UI to get all the data needed, this can be provided to a backend team as a spec or even integrated in a tool like Pact to do contract verification in a CI/CD pipeline. This session also covered WireMock, which is a more general-purpose solution to mocking API requests that could work for both a web UI or a microservice that needs to call other APIs. The focus of this session was on enabling manual testing, however adapting it to automated solutions can be done more easily once an application is truly isolated.

The Main conference
The final two days are the main event at Code Mash, with more people and sponsors lining the hallways with tables of swag. Sessions are hour-long talks rather than in-depth workshops, and they run continuously, creating a choose-your-own adventure day. Throughout the conference, there are even retro boards to collect real time feedback from anyone, especially people that want a bacon bar next year.
Data Structures Crash Course
Presented By: Jordan Thayer
This course covered a variety of algorithms, and how to analyze their complexity. Many of these algorithms are clever uses of tree data structures to detect sprite collisions or find similar items in a catalog. There was also a dive into how a hash table works, the importance of a good hashing algorithm in maintaining fast lookups, and the hidden costs around table expansion.
Domain-Driven Refactoring
Presented By: Jimmy Bogard
This was a step-by-step walkthrough of turning a more procedural coded service with anemic models (that looks like a lot of codebases) into well-formed domain models that encapsulate data and functionality. More importantly, this course also covered several good enough stopping points where additional effort to get a better domain model may not always be worth the effort.
Using GPT Visual Capabilities to Solve a Wordle Puzzle
Presented by: Jennifer Marsman
This presentation was a behind-the-scenes look into the process Marsman followed to create a tech demo presentation for GPT to solve wordle given an image of the guesses. She explained her thought process in how to get the model to do several difficult things at once. Whether it was using a few shot approach to help give context or bracketing letters in the prompt so they get tokenized separately. In the end She was able to demo the finished result with the days wordle and we solved it in three guesses.
The Agile Architect: Building Product From the Trenches, Not the Tower
Presented By: Brandon Suponchick
This session started with a comparison of the Agile Architect to that of Gandalf in lord of the rings. An Agile architect works alongside the team and leads them towards the goal. They trust the team to be competent to handle the small problems and can jump in for the big ones. They have years of experience in a wide variety of skills that they can leverage to make decisions and guide others. The agile architect is as much a teacher as they are a doer. They don’t stay in the trenches all the time though; the architect needs to spend time in the tower with leadership being the advocate for the development teams.

Making Great Waves: 8 Software Testing Convictions
Presented By: Andrew Knight
This presentation uses the Japanese art of Ukiyo-e to discuss actions and processes that everyone should follow in software development and testing to make better software.
1. Focus on behavior.
2. Prioritize on risk.
3. Automate.
4. Shift left and right.
5. Give fast feedback.
6. Go lean.
7. Open up.
8. Show empathy.
Onboarding and Mentoring: A surprising Winning Combination
Presented By: Connor Robinson
This presentation covered several ideas that can help make onboarding more successful. From the obvious make sure you have a computer on day one, to avoiding automated scripts that may or may not be working at the time of a new hire. Encourage new hires to update or call out bad documentation, make sure they get one on one time with everyone on their team. A poor onboarding experience can lead to increased turnover if new employees aren’t feeling like they actually belong.
5 Questions to Get You Started With UX
Presented By: Burton Smith
By working though these five questions and their answers, it can help inform what you need to build for your users to get the desired outcomes. This can sometimes lead to surprising solutions, as complaints by users or ideas about who your users are aren’t always accurate. These principles are also not limited to just building software, and they can be widely applied to almost any domain.
1. Who is the user?
2. What are they trying to accomplish?
3. How can we help them do that?
4. What do we want the user to do?
5. How do we incentivize them to do that?
Strengthening Your Foundation: The Power of Architectural Testing
Presented By: Michael Eaton
This session demonstrated using a couple test frameworks NetArchTest and ArchUnitNET that can be used to help ensure the integrity of a codebase through automated testing. Instead of functionality, these frameworks focus on ensuring relationships and design are maintained. Examples of this are ensuring various layers don’t rely on each other or naming rules for different objects are followed. These frameworks are a way to help ensure that code bases don’t evolve into a ball of mud as time passes and more features are added.
Highlights of Code Mash 2025 was originally published in Criteo Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
I recently ran into some problems with my editor config around vim-projectionist. Of course the fix was super easy - there was invalid JSON in my .projections.json file. This vim plugin is a core part of our workflow at Hashrocket, so I wanted to figure out a way to prevent this from happening again. So today, I want to propose 2 solutions that will help you easily catch those pesky JSON errors in your editor.
1. Install a JSON language server
This may seem obvious, but I'm sure it can be overlooked during initial setup. Catching the errant trailing comma or other issues can be surfaced very quickly, while you're editing the file.
If you're using VSCode, there's vscode-json-languageserver. Just add it to your plugins and you're good to go.
If you're using Neovim and nvim-lsp, there's jsonls which you can configure in your init.lua.
2. Payload Validator Script
The alternative to either of these is to write a small script to validate your .projections.json payload when present and give feedback within your editor.
Let's assume you are using nvim without LSP or other validation plugins. Here's something I whipped up rather quickly -
First, I made a ruby script to load and parse the projections file when present. If there's a projections file with JSON errors, we exit with code 1, otherwise 0.
require "json"
class BasicObject
def blank?
self.nil? || self.to_s.strip == ""
end
end
project_dir = ARGV[0]
custom_projections = File.join(project_dir, ".projections.json")
if project_dir.blank? || !File.exist?(custom_projections)
exit 0
end
begin
JSON.parse(File.read(custom_projections))
exit 0
rescue JSON::ParserError
puts "Invalid JSON detected in .projections.json"
exit 1
end
You can manually run the script from the command line to test things out.
ruby projections_check.rb ~/Hashrocket/hashrocket.com
Next, we setup a lua function to run our script and check the exit code. If it's non-zero, then we notify the user with the error message.
local function run_script_with_cwd(command, cwd, error_message)
-- Run the command and capture the exit code
local exit_code = os.execute(command)
-- Check the exit status
if exit_code ~= 0 then
vim.schedule(function()
vim.notify(
error_message .. " " .. exit_code,
vim.log.levels.ERROR
)
end)
end
end
-- Check if a projections file is defined and valid JSON
local config_dir = vim.fn.stdpath("config")
local projections_check_script = config_dir .. "/projections_check.rb"
run_script_with_cwd(
string.format("ruby %s %s", projections_check_script, vim.fn.getcwd()),
vim.fn.getcwd,
"Custom .projections file is invalid"
)
And that's it! To test out the whole thing, I setup some invalid json in my projections file. The next time we open nvim with invalid projections, we are notified that the projections file is invalid.

Happy Hacking!
Backstory
A few years ago, I designed and set up a GraphQL server at Deezer. Among all the challenges I faced, one was related to performance. Designing a GraphQL server that is both convenient to use and performant is not an easy task, especially in Node.js.
One of the optimizations we made with Jimmy Thomas was to use GraphQL JIT instead of the default GraphQL execution engine.
The README claims to improve response time and increase the number of queries that can be executed per second by reducing the CPU time it takes to compute a single query.
What is GraphQL JIT
GraphQL JIT is a Just-In-Time compiler for GraphQL queries. It is designed to take advantage of V8 optimizations to increase performance. It is a drop-in replacement for the default execution engine of GraphQL, with a few restrictions.
One of the most important is stated in the project’s README:
All computed properties must have a resolver, and only these can return a Promise.
Depending on how you design your server, this limitation may or may not be an issue.
In my case, it was not an issue at all.
The performance gain claim is pretty impressive: up to 10 times faster than the default execution engine.
Why we switched
At the time, we conducted extensive tests on the project and used Gatling for load testing. I specifically crafted some reference queries and used them to compare the performance of all the changes made. This way, we could improve response time and admissible load bit by bit. One of the most important changes was the adoption of GraphQL JIT. The performance gain was substantial enough to make it worth the switch at the time.
Unfortunately, all reports and graphs were purged, thanks to Jenkins’ cleaning policies.
Why reconsider it now?
When we conducted the tests and made the switch, the project was barely used. I completely relied on my test queries for benchmarks. Those queries were built to be representative of a theoretical usage, but they were not real queries as no clients of the API existed yet.
Now, the API is live and in use. I have real-world queries to analyze, and I can observe the server’s performance in real-time with real clients.
So, let’s revisit this choice and see if it is still the right one.
Test methodology
Two tests are in order:
- One in production with real customers queries
- One using the old method with Gatling, as before
Production test
To test the two engines simultaneously, I modified the server’s code to randomly start with one engine or the other. When deployed onto the Kubernetes cluster, multiple instances of the service will be started — enough from both engines to gather significant statistics.
The code is quite barbaric but works wonderfully:
expressApp.use(
[…],
Math.random() > 0.5
? createJitGraphqlMiddleware({schema})
: createJsGraphqlMiddleware(schema),
);
Once in production, I will analyze metrics to evaluate the impact of each engine. I will primarily focus on:
- System metrics such as CPU and memory usage
- Node.js system metrics such as Event Loop Utilization (ELU), HEAP size, and Garbage Collection
- Response time goals (how much it deviates from the target)
- Average response time and 95th percentile
Lab tests
For the lab tests, I will use what’s already available from my previous tests years ago. I’ve set up Gatling with a few typical queries. The queries and rate of fire are not exactly the same as before because, over the years, I’ve tuned them to be more representative of the real world. When I say “more representative,” I don’t mean they are truly representative. Instead, I’ve simply adjusted them based on our observations in the field and modified them in a way that makes them closer to the real world. Unfortunately, I have no way of confirming this; it’s far from scientific here.
The most notable change is the way scenarios are grouped. Previously, each query had its own rules during the test. Now, I’ve grouped them into two main categories, representing two typical client profiles:
- Light users send small queries. This is standard usage of the API, similar to how any customer would interact with our apps/front-end.
- Heavy users make large and complex queries with lots of fields and nested fields. This is typical of a customer using some costly features of our apps or any rogue client trying to abuse the API.
What’s important is that the two profiles do not fire queries at the same rate. One fires far more frequently than the other.
The final Gatling scenario looks like this:
val heavyUser_ConcurentUser = max_reqps/20
val heavyUser_ConcurentRequest = max_reqps/20
val lightUser_ConcurentUser = max_reqps - heavyUser_ConcurentUser
val lightUser_ConcurentRequest = max_reqps - heavyUser_ConcurentRequest
setUp(
lightUser.inject(
rampConcurrentUsers(1) to (lightUser_ConcurentUser) during (2 minutes),
constantConcurrentUsers(lightUser_ConcurentUser) during (duration - 2 minutes)
).throttle(reachRps(lightUser_ConcurentRequest) in (duration minutes)),
heavyUser.inject(
rampConcurrentUsers(1) to (heavyUser_ConcurentUser) during (2 minutes),
constantConcurrentUsers(heavyUser_ConcurentUser) during (duration - 2 minutes)
).throttle(reachRps(heavyUser_ConcurentRequest) in (duration minutes))
).protocols(httpProtocol)
The Gatling tests will run on my laptop but will target instances of the server deployed in a development Kubernetes cluster. This cluster is similar to the one in production in form and configuration but not in size. I won’t push the cluster to its limits, so I’m not concerned about the results being skewed by the environment.
I will monitor the same metrics as in the production test. This time, I will not consider the results from Gatling itself because I am running the tests from my laptop and cannot trust the response times gathered by Gatling. Moreover, I don’t really need them.
Results
Production results
— Response times
One of the metrics I have is the time it takes for the engine to compute a request and produce a response.
It does not include the time it takes to send the response to the client or network delays.
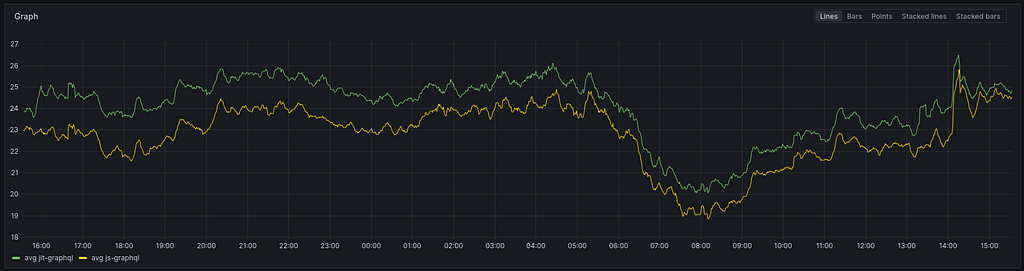
The average response time shows that the JS engine is slightly faster, but with only a one-millisecond difference, it’s not really significant.
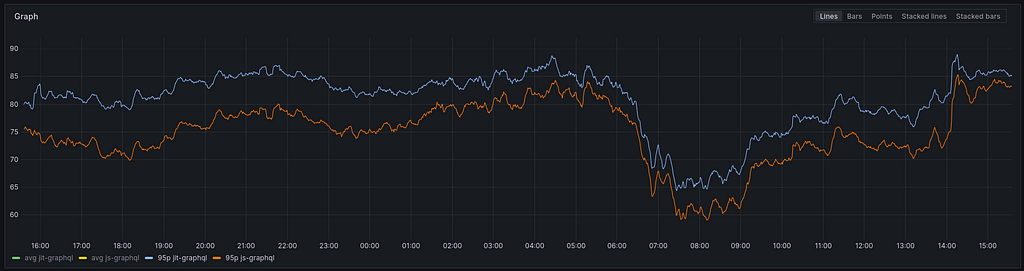
The 95th percentile shows a somewhat greater difference. It is not enormous, but five milliseconds does feel significant.
Regarding response time, we can say, without any doubt, that the `JIT engine’ is not worth it, mathematically speaking. However, we are talking about a five-millisecond difference, so it is not really a big deal either.
— System metrics (CPU & RAM)
The service is deployed on a Kubernetes cluster. I have access to the cluster metrics and can see how much CPU and RAM are used by the service.
In Kubernetes, we set CPU and RAM reservations. It is a good practice to indicate to the cluster how many resources the pods will need.
For example, we can define that one Node.js process can use up to two CPUs.
The graph then shows how much of these two CPUs are used compared to the reservation.
The same applies to RAM. Of course, the graph shows values for the entire cluster, not just one pod.
```yaml
limits:
memory: 512Mi
requests:
memory: 512Mi
cpu: 2
```
This is an example of a configuration for a pod. This means the pod will have two CPUs and 512Mi of RAM at its disposal.
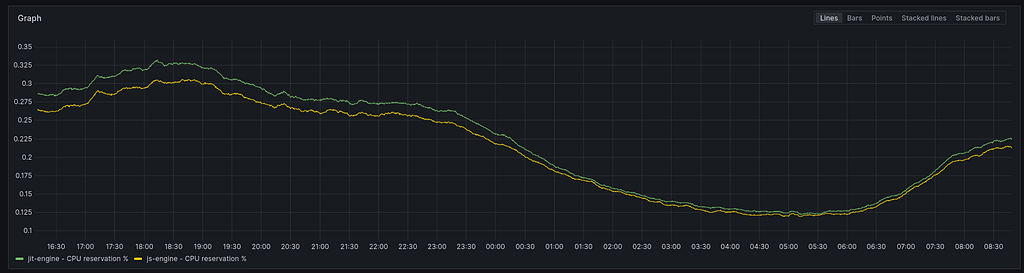
The `js-engine’ uses 2% less CPU than the `JIT-engine.’ It is a consistent difference, but like the response time gain, it is not that significant. Don’t get me wrong, when you deploy hundreds or thousands of pods, 2% can mean a lot, but I’m not convinced it does in my case.
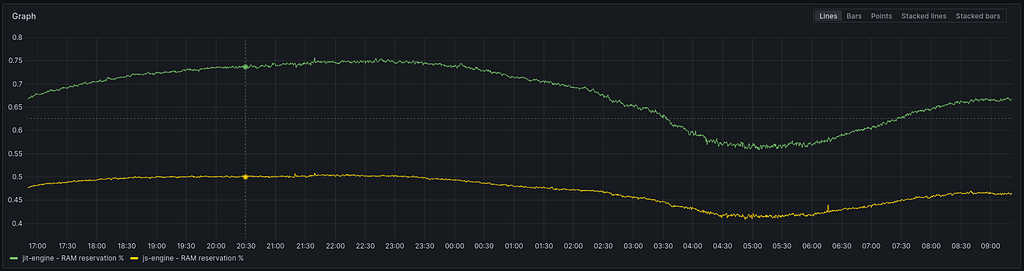
The RAM usage is a bit more interesting. The `js-engine’ uses ~20% less RAM than the `JIT-engine.’ Here, a 20% difference feels substantial.
— Node.js metrics

I challenge you to identify when the deployment occurred. The ELU (Event Loop Utilization) did not shift a single bit, even with 50% of the requests being handled by the `js-engine.’ This graph only shows the overall cluster level, as I cannot get metrics for each engine separately. In my opinion, since 50% of the pods use another engine, if the ELU were significantly impacted, we would see it. I will assume that using either `JIT’ or `js’ does not change anything in terms of Event Loop Utilization.

Monitoring the HEAP shows that the `old’ space seems to have reduced slightly. It is not very obvious in the graph but it is visible in the average. The maximum did not change, but the minimum did. This confirms what we observed earlier with RAM usage.
Other HEAP spaces were not impacted at all, and the same goes for Garbage Collection. They all tell the same story as the ELU metrics. They remain unchanged from before, so I didn’t bother screenshotting the graphs.
Lab results
I ran the Gatling test for each engine in two separate deployments. The tests were run simultaneously. Strictly speaking, they could have impacted one another, but I don’t think this effect is significant, as the cluster I was using had enough resources to handle the load. Moreover, the load was not that high, and I kept the request rate well below limits.
— Response times
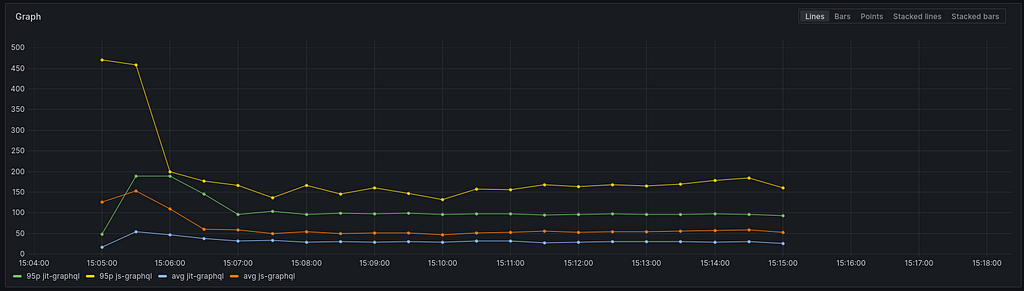
The results are not favorable for the `js` engine. The difference is substantial. We must remember that this is a lab environment, and response times may differ from those in production. However, we are losing about 50 milliseconds on the 95th percentile and 20 milliseconds on average. These represent slowdowns of approximately 50% and 70%, respectively, compared to the `JIT’ engine.
— System metrics (CPU & RAM)
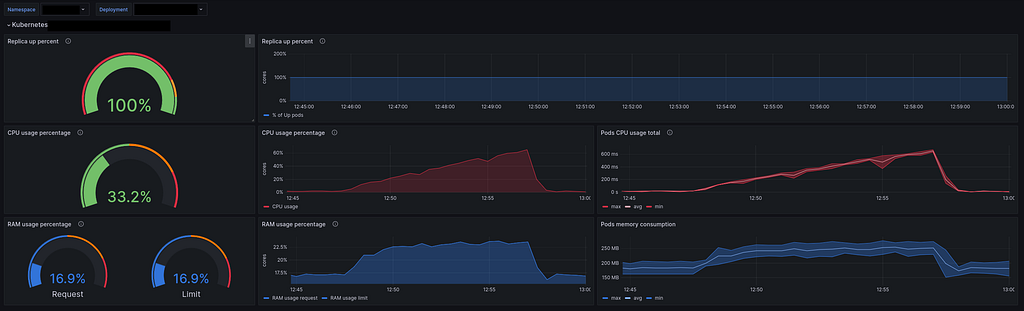
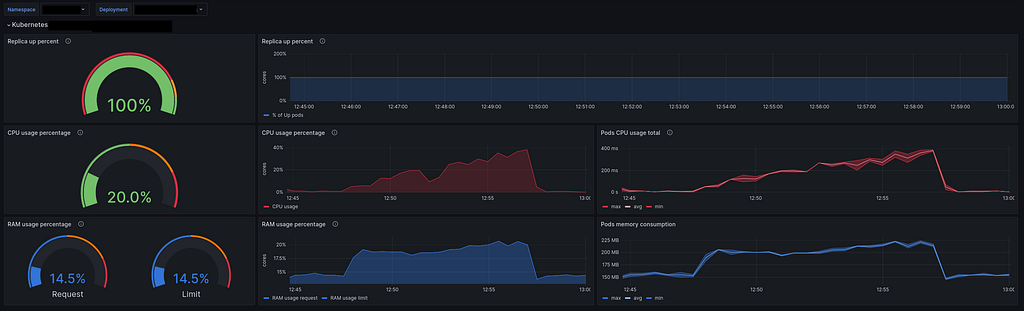
The first notable difference is in CPU usage. The `js-engine’ uses 20% more CPU than the `JIT-engine,’ which is significant.
Regarding RAM, the difference is smaller but still present, with only a few percentage points of increased usage for the `js-engine.’
Overall, our synthetic tests indicate that the JIT engine is more efficient than the JS engine.
— Node.js metrics
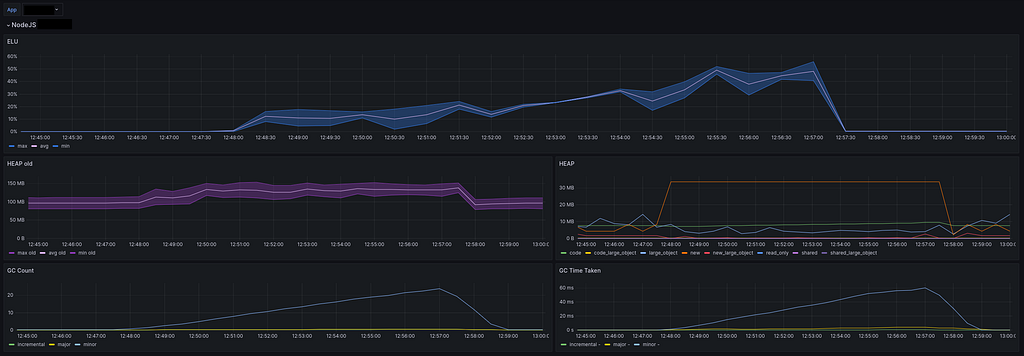
The story remains consistent with the Node.js metrics. The `js engine’ uses more HEAP, more Garbage Collection, and has a higher Event Loop Utilization (ELU). Specifically, the ELU increased from 30% to 50%.
What is the meaning of all of this?
Okay, things are getting interesting. The production results clearly show a slight advantage for the `js’ engine. This win is small and could, in some cases, be considered negligible. However, it is still a win. On the other hand, the story is entirely different when we look at the lab results. The `JIT’ engine is a clear and substantial winner! Moreover, based solely on the lab results, it is a no-brainer to use the `JIT’ engine.
The lab results were essentially the same as those I had years ago. The `JIT’ engine is faster, more efficient, and requires fewer resources in a lab environment. Back then, I only had those results to inform my decision and naturally chose the `JIT’ engine.
Today, however, the production results complicate the decision:
- The `js’ engine is better or at least as good as the `JIT’ engine in terms of response time, resource usage, and overall performance.
- The complexity introduced by the `JIT’ engine has a cost.
- The `JIT’ engine has certain limitations. We did not encounter these, so they may not be highly relevant in my context.
- The `js’ engine is effectively the “standard.”
The question has been raised internally, and there seems to be a consensus that standardization is important enough to justify switching back to the `js’ engine. I tend to agree with this perspective.
Why does the optimization not show up in production?
The production and lab tests have opposite behaviors that feel counterintuitive. I believe the main reason lies in how we utilize the GraphQL API.
When we began our GraphQL journey, we had a steep learning curve. One of the biggest challenges was designing the schema and envisioning the queries that would be made. We had to rethink everything, moving away from our accustomed REST APIs.
However, as anyone who has worked on an existing system knows (do I hear “legacy”?), we had to consider many existing scenarios and technical limitations. For example, paginated results were not as common back then as they are today. When designing the schema, we aimed to follow the “state of the art” in this regard, but it was not always straightforward or even feasible.
After years of learning and striving towards best practices in GraphQL, we find ourselves in a much better situation than expected. For instance, we initially feared processing massive queries with numerous nested fields. This concern hasn’t completely disappeared, but looking at the queries generated by our apps, the reality isn’t as daunting as we imagined.
Teams have adapted to the new way of thinking, embracing the limitations and concepts of a GraphQL API. Gradually, they’ve accepted the need to approach things differently. The quality of our GraphQL queries seems sufficient, indicating that we no longer require the `JIT’ optimizations.
One of the best use cases for `JIT’ appears to be when dealing with complex queries that have many nested fields. We currently don’t have that issue, or at least not to a significant extent.
In the future, we may need to reassess this decision based on how we develop our upcoming applications and frontends. But for now, the `js’ engine seems more than adequate.
Conclusion
A few years ago, I designed a GraphQL server and made several architectural decisions. We implemented some obvious optimizations and conducted tests to verify their effectiveness beyond marketing claims, confirming our choices.
Not all decisions were perfect, and there is much to discuss and critique about the project. However, the choice of the ‘JIT’ engine was a good one at the time.
Today, the context has evolved. We have (enough) real-world clients, and both Node.js and V8 have been improved. Additionally, the standard implementations of GraphQL have benefited from years of community enhancements.
Revisiting old decisions has proven to be insightful, if not beneficial. The ability to test a theory in production easily and without the fear of breaking anything is a luxury. I’m grateful for this opportunity.
Ultimately, we can conclude that the real world always surpasses the lab and its benchmarks. While this may not come as a surprise, it’s always a good reminder. If you have the resources and time, take the opportunity to test your hypotheses using real-world data or actual clients whenever possible. For this, it’s crucial to maintain healthy development practices that facilitate easy and safe testing and deployment.
In conclusion:
The ‘JIT’ engine seems to be worthwhile. However, I would recommend conducting proper tests, if feasible, before fully committing to it. Gains may be small or even imperceptible, depending on your circumstances.
Anyway, always monitor, metrics are essential!
—
Many thanks to Pauline Munier and Gillian Kelly for their help in writing this article.
You can also find this article, a French version of it, and more on my personal blog https://blog.ztec.fr/en/.
GraphQL JIT, is it worth it? was originally published in Deezer I/O on Medium, where people are continuing the conversation by highlighting and responding to this story.
Authored By: Christopher Fuller
At first glance, Tinder might seem like a simple application. After all, Tinder is best known for its iconic Swipe Right feature, a simple gesture that revolutionized how people express interest and connect. But when you look under the hood, there are a lot of complexities to consider when building the experience that our users know and love today. People around the world indicate billions of Likes and Nopes per day, across a wide variety of iPhone models and screen sizes. When we roll out just one feature update, we have to understand how it’ll impact every user on whatever device they’re accessing the app from. I find this to be uniquely challenging, interesting and rewarding work.
As part of an initiative to contribute more to the software development community at large, I’m really excited to announce that we recently released our Layout code repository to the open source community. We are now publishing a few additional repositories as well.
We felt it was important to share what has worked well for our team in recent years. Both Layout and our mobile application architecture, Nodes, have long been essential parts of the Tinder iPhone app and its success to date. Before we explore our Layout repository in more detail, here’s some context for how we got here.
How we got here
As Tinder grew in complexity, we repeatedly encountered challenges with reliability and performance in the iPhone app. To mitigate this, we focused our attention on extensibility, consistency and memory use. It quickly became clear that we needed to empower our engineers to continually add new features to the app safely without breaking existing functionality. The solution we devised, called the Nodes Architecture Framework, is a plugin-based approach which allows new app screens to be integrated into existing screens with only four lines of code.
A plugin validates the conditions that dictate whether a feature should be enabled. A single factory method call to “build” a feature is made possible using dependency injection code-generated at compile time. The logic of the feature is contained within a “context” object separate from the view to allow business rules to be tested in isolation. The context assumes the role of an interactor and responds to events, such as user actions. All output signals from a feature are received by the context object via delegation, uniquely referred to as a “listener” delegate. In other words, if screen A presents screen B, this means context A “listens” to context B. And a “flow” object assumes the role of a router responsible for starting other flows, as you can see in this example.
guard let builder = plugin.create() else { return }
let flow = builder.build(withListener: context)
viewController.present(flow.getViewController(), animated: true)
attach(starting: flow)A side-effect of this approach is that plugins can be trivially added to plugin collections, known as “plugin lists”, for feature versioning or A/B testing. The integration call-site does not need to know or care which version or variation of the feature is then built and started.
guard let builder = pluginList.create() ...
To optimize memory use, we introduced the concept of lifecycle to each feature. Dismissing a screen is an important lifecycle event that signifies that all memory for that feature must now be released. Debug builds can tap into this hook and warn when memory leaks occur.
await viewController.dismiss(flow.getViewController(), animated: true)
detach(ending: flow)
We also developed custom Xcode templates to provide scaffolding when creating a new feature. This has fostered consistency across feature implementations to enable effortless context switching and ease of debugging common issues. The Nodes repository includes the generator that creates these Xcode templates.
The graph below is particularly interesting because it shows how adoption of the legacy architecture immediately flattened out the moment Nodes was released. As adoption of this new architecture was not mandated, this graph demonstrates that our teams immediately found Nodes to be beneficial and saw value in moving away from the legacy architecture.
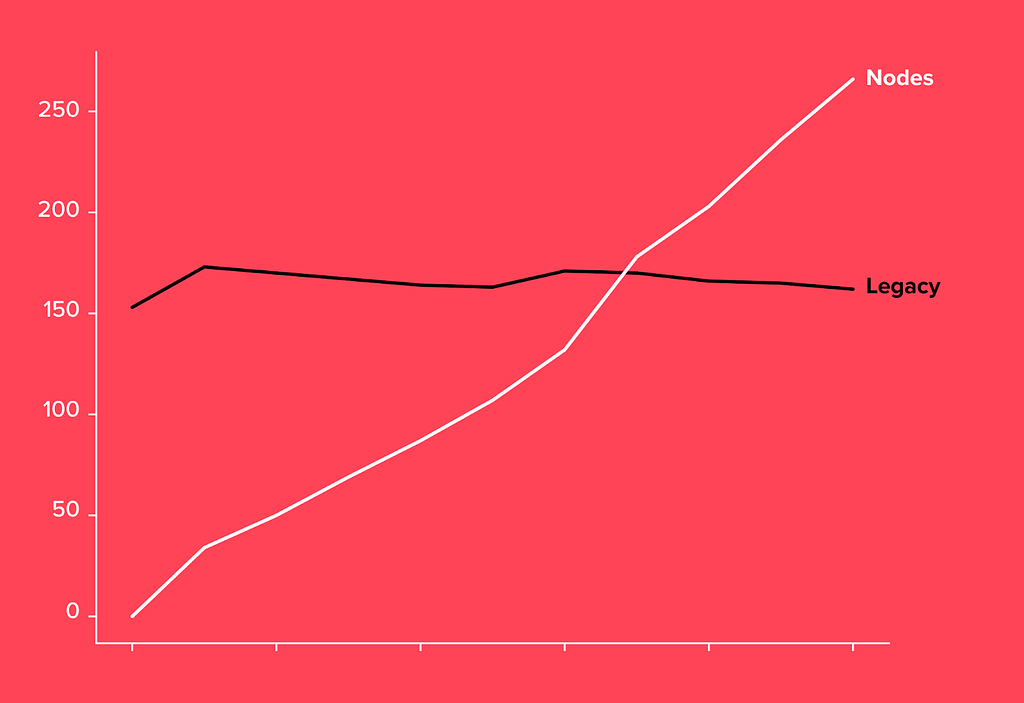
— Nodes adoption since its introduction at the beginning of 2020 as compared to legacy architecture.
Why Layout was critical to our success
While the Nodes framework provides essential structure for our mobile engineers to architect their features, one of the most important aspects they focus on next is how the screens of the app look.
Since the Tinder iPhone app has been primarily built with UIKit, and we wanted to make it as easy as possible for our engineers to define UI layouts, we developed a new high fidelity DSL syntax, called Layout, to easily visualize the screens the code represents.
In the evolving mobile development landscape, declarative UI frameworks such as SwiftUI and Jetpack Compose offer benefits such as significantly reduced learning curves. While not a declarative framework, Layout utilizes a similar declarative style, in this case for the UIKit framework.
We’ve used Layout, a wrapper around Apple’s Auto Layout SDK, as part of our iPhone codebase since 2017 to programmatically define the screens of the app.
There are several key advantages to Layout that have enabled our developers to build the best-in-class user interface that our users expect each time they open the app:
- Less verbose code — Layout is a great example of the type of programmatic UI code typically used in projects with large codebases.
- Easy to use — Layout avoids unmanageable conflicts that are encountered with XML, the serialized format of Xcode storyboards.
- Flexible and compatible — Layout doesn’t limit UIKit’s native Auto Layout capabilities which may therefore be used directly in concert with the Layout API.
This style of layout, where the relationship for the top is defined first, then the horizontal relationships, followed by the remaining vertical relationships, is very readable and has been ideal for many screens.
view.layout {
label
.toSafeArea([.top])
.center(.horizontal)
imageView
.toSideEdges(inset: 20)
.height(200)
button
.center(.horizontal)
}
.vertical([label, imageView, button], spacing: 50)User interactions in layouts
When it came to wiring up user interactions to the UI elements of a UIKit based layout, there was an opportunity to combine (no pun intended) two modern Apple technologies, Combine and Swift property wrappers, to easily bind controls for user interactions and touch events. A reactive approach is not a new concept in mobile development but has always required 3rd party reactive libraries, such as RxSwift. Now this can be done natively, for example with our CombineUI library, seen here integrated with our Collection Builders library.
@Button var button = UIButton()
cancellables.insert {
title.bind(to: button.bindable.title(for: .normal))
$button.sink { print("Tapped") }
}
A unified approach to mobile app development
When considering the Nodes Architecture Framework, Layout and CombineUI holistically, the combination of the plugin based architecture with scaffolding, the declarative layout syntax and the reactive API together represent a unified approach to mobile application development on Apple platforms. These projects help us to mitigate reliability and performance issues and empower our engineers to support Tinder’s mission and provide value to our users on iPhone devices.
And these are also the reasons why we are publishing the code repositories to GitHub. While we know this may open our team and development principles up to some amount of scrutiny, we’re sharing these repositories to show the open source community what has worked well for us and contributed to Tinder’s success up until now. We also look forward to leveraging community feedback to enhance our mobile experiences, now and into the future.
What’s next
Our iPhone app codebase has evolved into a hybrid model, incorporating SwiftUI for some new features alongside UIKit. And while our architecture provides an ideal pattern for incrementally adopting SwiftUI using the same plugins and scaffolding to provide consistency in features no matter which UI framework is used, we are excited to evolve our patterns and practices over the coming years. This will allow us to take advantage of the full power of SwiftUI and the latest SDKs and guidelines from Apple.
Below you will find links to the repositories mentioned in this blog post along with a few other Tinder projects you may find interesting. The Swift packages are also available in the Swift Package Index.
Nodes Architecture Framework
Native Mobile Application Engineering at Scale
https://github.com/Tinder/Nodes
Layout
High Fidelity Auto Layout Result Builder Syntax for UIKit
https://github.com/Tinder/Layout
CombineUI
Swift Property Wrappers, Bindings and Combine Publishers for UI Gestures, Controls and Views
https://github.com/Tinder/CombineUI
Collection Builders
Swift Result Builders for Array and Set
https://github.com/Tinder/CollectionBuilders
Commit Message Validation Hook
A lovely little git hook to validate commit messages
https://github.com/Tinder/Commit-Message-Validation-Hook
spellcheck-cli
A tiny command line script to check the spelling of text on macOS
https://github.com/Tinder/spellcheck-cli
Nodes Tree Visualizer
A handy tree visualizer for apps using the Nodes Architecture Framework
https://github.com/Tinder/Nodes-Tree-Visualizer
bazel-diff
Performs Bazel Target Diffing between two revisions in Git, allowing for Test Target Selection and Selective Building
https://github.com/Tinder/bazel-diff
sign-here
A straightforward tool that enables the creation of Provisioning Profiles and Certificates for deploying Apple based software
https://github.com/Tinder/sign-here
Special thanks to the following contributors who made these repositories possible:
(in alphabetical order)
- Kyle Bendelow
- Micah Benn
- Cole Campbell
- Maxwell Elliott
- Caio Fonseca
- Christopher Fuller
- Siddarth Gandhi
- Eman Harout
- Sam Marshall
- Matthew Mourlam
- Garric Nahapetian
- Igor Novik
- Connor Wybranowski
Announcing Tinder’s latest contributions to the open source community was originally published in Tinder Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
In March 2023, Wise launched its new brand — as part of it, we introduced a collection of bold new 3D illustrations. While visually stunning, our brand team had bigger ambitions to bring them to life and elevate Wise further.
This took us on a journey to understand the technical landscape and challenges around creating a seamless multi-platform solution for interactive 3D animations.

The new illustration set in Wise
Our new illustration set took inspiration from icons, allowing us to communicate with a global audience. They’re unique, bold and dynamic, even when still.
They give us opportunities to share moments of delight with our customers and help our brand stand out from billboard to button.

What sets illustrations at Wise apart is that they’re not static. Each one is paired with a crafted 3D model, featuring detailed UV maps, precise shading, and carefully designed lighting.
This raises an exciting question: What if we rendered these illustrations dynamically in real time, making them interactive on mobile apps?
Native or web view?
To render illustrations in real time, we explored several technical solutions:
We opted to create 3D scenes using three.js, one of the most popular open-source web projects. Some of the reasons behind this include:
- Managing native solutions for iOS and Android platforms would demand extra engineering effort.
- The support and documentation available for three.js surpass others.
- The web view solution delivers native-like performance by using WebGL on both platforms. As a result, we consistently achieve 60/120 FPS across all scenes on both devices.
The plan was simple. Build simple HTML files that render 3D scenes and load these files locally in mobile apps 🚀
But we had a “huge” problem…
The 3D models were specifically designed for static illustrations, resulting in a high polygon count that contributes to larger file sizes. For instance, the glTF file for the plane model is approximately 19.3 MB. In total, the original file size for all the 3D scenes we support was around 324 MB.
To make these files suitable for mobile apps, we had to optimise and compress them extensively.
Optimisation #1 — Remove duplicate images
The first optimisation we have to remove the duplicate textures in glTF files.

Both padlock and globe scenes use the common blue texture. If we loaded glTF files directly we would duplicate the texture in mobile app bundle.
To address this issue, we followed these steps:
- Extract the embedded images from the glTF file.
- Eliminate any duplicate images.
- Recreate each glTF file, ensuring that it references the image files correctly.
As a result, we successfully reduced the overall asset size from 324 MB to 98.4 MB. While this was a significant improvement, we were confident that we could achieve even better results!
Optimisation #2 — Compress textures
The original textures extracted from the glTF files were huge. To enhance performance and to reduce the bundle size on mobile apps, we prioritised optimising textures over maintaining high-quality versions. Therefore, we were able to significantly compress the textures.

As a result of compressing textures, we managed to further reduce the overall asset size from 98.4 MB to 5.2 MB. While this was impressive progress, we knew we could do even better!
Optimisation #3 — Compress geometry data
The last step was to compress geometry data and to reduce the glTF file size. We compressed each model using an open source library Draco from Google.
Now with this final optimisation, we successfully reduced the overall asset size from 5.2 MB to 3.7 MB.
324 MB > 3.7 MB
After implementing all optimisations, the final mobile bundle size was reduced from 324 MB to 3.7 MB!
This new size was a significant achievement, given the mobile bundle consists of glTF model files, textures, JS libraries (three.js and draco.js) and HTML files.
All of these optimisations are fully automated through a dedicated internal repository that houses our entire optimisation pipeline. This setup enables us to add new 3D scenes more efficiently and quickly.
Displaying 3D scenes on mobile apps
Each 3D scene is contained within a standalone HTML file, which loads JavaScript libraries and assets locally. These scenes are then displayed in mobile apps through web views.
By rendering scenes on WebGL using three.js, we achieve a smooth 60 to 120 FPS, ensuring excellent performance on modern mobile devices without any issues.
One of the biggest challenges on both platforms was the delay in loading scenes. Since we heavily compress models using the Draco library, decompression takes time. To address this, on both platforms, we pre-load the scenes, store them in memory while rendering is off. This approach ensures instant loading times for a seamless user experience.
Both iOS and Android platforms have abstracted the integration of these 3D scenes. When a mobile engineer wants to use a 3D scene, they simply specify the desired 3D scene, and our UI components handle the rest automatically.
Interactivity on mobile apps
HTML files featuring 3D scenes also support interactivity, offering APIs to control various aspects such as starting or stopping rendering, managing animations, and adjusting rotation.

Mobile apps gather rotation data using their internal gyroscope natively and send this information to the HTML files, enabling the animation of rotation in the 3D scene.
And that’s it! This is how we turned a simple idea into an actual feature and made our illustrations 3D interactive!

A big thank you to Chao Quan Choo and Ness Grixti for their hard work and dedication in pushing this project forward and making it happen!
A big shout out to the folks at Ragged Edge for their amazing work in designing the illustrations!
Onwards 🚀
How did we build 3D animations in mobile apps? was originally published in Wise Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
Today, we’re spotlighting Komaron James, who has been with Gusto for one and a half years as the PE (People Empowerer or People leader) for Gusto Embedded API infra team.

Abby: How did you join Gusto?
Komaron: My journey began as a software engineer fresh out of college. Like many new grads, I was eager to move fast and work with the latest technologies. I accepted an offer from a large company and soon learned from my future manager that, while big companies provide consistency and structure, they also tend to move at a slower pace.
Although I valued the experience and the opportunities it offered, I quickly realized that this wasn’t the long-term path I wanted to follow. Instead, I decided to explore the startup world. At the time, startups were booming, and a friend recommended that I join one. That’s when things really started to accelerate for me.
Over the last 10 years, I’ve worked at various startups across different industries. One common thread across all these experiences was the challenge of navigating the transition from early-stage to growth-stage, especially when it came to managing payroll and HR software. Interestingly, at every company I worked for, Gusto was part of the solution, and as a user, it quickly became one of my favorite tools. I’ll never forget Penny the Pig, Gusto’s mascot, which added a fun and memorable touch to the product experience.
Fast forward to 2023, I was looking for new opportunities where I could continue to make a meaningful impact and empower people through software. At that time, I saw that Gusto was actively hiring, and their mission to support small businesses immediately resonated with me. I applied, everything aligned, and I joined Gusto.
Abby: In your role here at Gusto, what has been one of your proudest accomplishments/impacts you have had on the small to mid-sized (SMB) customers we serve?
Komaron: What I’m most proud of is our ongoing effort to enhance the experience for developers integrating with Gusto. Since joining, we’ve focused on making our APIs and developer tools more consistent, reliable, and scalable. These improvements directly empower our partners to create exceptional experiences for their customers and end users. Developers depend on us to provide accurate, well-documented, and reliable tools so they can focus on building innovative solutions.
For example, API versioning helps our partners stay informed about upcoming changes and understand the reasons behind them, especially regarding security and vulnerability fixes. We’ve also worked to improve documentation on READMEs and make our webhooks more robust. These are just a few of the ways we’re continually improving the developer experience.
Abby: How has Gusto played a role and supported you in your journey as an engineer manager?
Komaron: Gusto has supported my growth by creating an environment where mentorship and collaboration are key priorities. I’ve had the opportunity to lead projects such as setting API standards and managing version deprecation efforts, which have really helped me level up in systems thinking and figure out how to influence beyond just my own team. It’s been awesome to work somewhere that pushes me to grow while giving me the space to take on big challenges.
Abby: What makes you excited about the work you do to serve SMB customers here at Gusto?
Komaron: My father also runs a small business and experienced firsthand the challenges of growing from a single entity to a larger operation. Gusto helps its customers focus on their vision rather than getting bogged down with the tools needed to manage payroll or employee benefits. SMBs often face these challenges with limited resources, yet they remain the backbone of our economy.
Abby: What advice would you give to someone looking to break into engineering or are just getting started?
Komaron: Focus on mastering the basics of problem-solving and communication. While technical skills are crucial, the ability to clearly express your ideas and collaborate effectively will truly set you up for success. Take on projects that push you to grow — I’m a firm believer that if something feels uncomfortable, it’s a sign that you’re learning. I learn these lessons every day. It’s one of the reasons I want to become a PE (People Empowerer) — to improve my communication skills. You can be incredibly smart and know all the tools, but without strong communication, you can only go so far.

Abby: What does your typical day at Gusto look like? What are your favorite parts of the day?
Komaron: My typical day as a PE (People Empowerer) is a mix of technical strategy and collaboration. Since I’m based on the East Coast and my team is distributed, my mornings are usually spent reviewing technical documents, collaborating on one-pagers, or preparing for upcoming meetings. In the afternoons, I’m typically immersed in meetings focused on refining our vision, aligning on our roadmap and strategy, and diving into technical discussions.
Later in the day, I have 1:1s with the people I directly empower, as well as with others outside my org for mentorship or to start early conversations about building public APIs. These moments of connection — whether it’s mentoring, brainstorming, or aligning on big ideas — are some of the most rewarding parts of my day.
Looking ahead, Gusto Embedded is a team focused on helping partners build seamless, customizable payroll and benefits within their own platforms for their SMB customers. We’ve developed a payroll API and pre-built UI flows to enable our partners to seamlessly integrate payroll and benefits into their product offerings and grow their businesses. There will be growing interest from other teams in building public APIs. We’ve already planned for this growth and are focused on finding ways to empower teams to successfully build those APIs.
My favorite part of my role are 1:1s, where I help individuals explore where they’d like to grow, how they want to spend their time, and how we can align those goals with the broader business strategy. But I also enjoy helping our teams make technical decisions because, at heart, I’m still an engineer.
Abby: What’s something that working at Gusto has taught you that you will continue to take with you in your career as you grow?
Komaron: Working at Gusto has taught me the value of fostering psychological safety within a team. Gusto has created an environment where asking questions, challenging ideas, and making mistakes isn’t just accepted — it’s actively encouraged. This culture of openness and trust has empowered my team to take bold risks, share diverse perspectives, and collaborate more effectively, all without the fear of judgment.
Abby: How have you sponsored other engineers? Is sponsoring other engineers an important aspect of your role?
Komaron: I’ve supported engineers in transitioning to staff roles by helping them focus on key areas like communication and collaboration.
For example, at my previous company, I worked with an engineer who had excellent technical skills and was considering moving into a PE role. I asked him if he was interested, but he was concerned about not being able to return to an individual contributor role once he made the shift. I gradually gave him more responsibilities aligned with the PE role, while continuously offering support. Today, this individual is still an engineering manager or technical lead.
This is just one example of how I’ve helped someone successfully transition from being an individual contributor to a leadership role by understanding the necessary skill sets and ensuring a good match.
Abby: What are some resources you’ve learned from? Any particular role models?
Komaron: When I became a manager, it came with a lot of challenges. I read countless books to gain context and gather useful tools, but what truly made the biggest impact was seeking out mentors. Listening to their stories and collaborating on overcoming challenges provided me with practical insights and the confidence to tackle difficult situations. Those conversations were invaluable in shaping my approach to leadership today.
I read and follow a lot of posts by Will Larson, who takes a systems thinking approach to engineering management. One of the books that particularly stands out is An Elegant Puzzle: Systems of Engineering Management.

Abby: What advice would you give to a senior engineer on how to start operating at the Staff+ level here at Gusto?
Komaron: Transitioning to a Staff+ role means shifting your focus from simply executing tasks to amplifying your impact. Seek opportunities to influence cross-functional decisions, take ownership of ambiguous problems, and mentor others to help them perform at their best.
Abby: Thank you so much for taking the time to talk to us!
Our interviewers are Abby Wagner and Leanne Lee. Abby Wagner works on Gusto’s Invite Team to hire software engineering talent, while Leanne Lee is a PE for Gusto Embedded Core API and Partnerships Engineering teams.
If you are interested in building solutions that solve real-world problems in an inclusive and diverse environment, reach out to us on our career pages!
Gusto Eng Spotlight Series: Komaron James was originally published in Gusto Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.

By Akshay Krishnaswamy & Ted Mabrey
The AI revolution is emerging at a crucial time for the Western world. The geopolitical chessboard is more complex than at any time since the fall of the Berlin Wall; institutions across the public and private sectors face a deepening legitimacy crisis; and as every enterprise fights to execute its essential mission, the pervasive feeling is that the last generation of technology investments have failed to meet their moment.
Whether protecting the nation, producing food, or delivering medical care, the diagnosis is similar: daily operations have exploded in complexity, and technology has not kept pace. Core business systems have ossified into straitjackets that constrain frontline workers. The endless SaaS solutions produced by the Software Industrial Complex have glittered the desks of managers while avoiding the friction of operational reality. The last decade of marketing and steak dinners have promised digital transformation, and instead delivered fragmentation and parasitic cost models.
With AI, enterprises have a generational opportunity to break these chains. The question is: what must be done differently to produce a worthy revolution?
Data vs. Process
Given that the goal is to transform the way the enterprise operates, the AI system must revolve around process — not simply data. Every consequential decision-making process involves interconnected stages, hand-off points, and feedback-driven learning. Think of how staff scheduling works in a hospital, how flight routing is performed by an airline, or how production is optimized on a manufacturing line. In these contexts, operational teams are dealing with time-sensitive tasks that require them to reason through different courses of action and execute decisions — often in dynamic situations with multiple stakeholders.
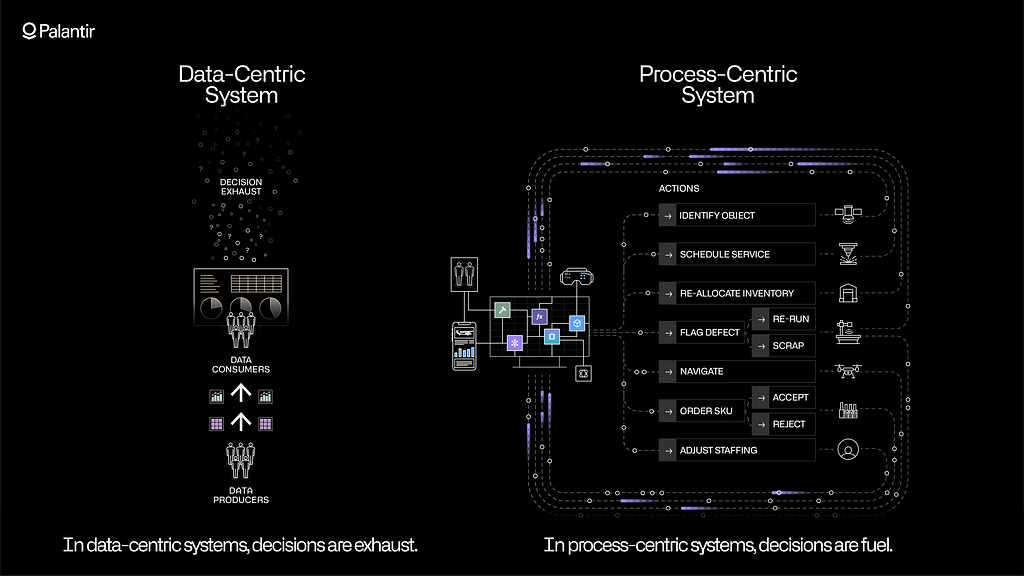
Software that is simply ‘data-centric’ can assist with aggregating information, creating dashboards, and bubbling up the occasional insight. This is managerial technology, in the original parlance of Silicon Valley; it is intended for offline analysis and keeping an eye on the metaphorical scoreboard. It is not designed to power inventory rebalancing, fleet positioning, or any critical frontline activity.
In the age of AI, the prospective value is not incremental; it is about fundamental transformation and the goal of driving automation into every core function. The data-centric architectures that enable ‘chat’ or ‘RAG’ workflows are streamlining information retrieval but fundamentally remain a one-way street of producing visualizations and insights. Infusing core workflows with automation requires an operational architecture where the process is primary and where progressively more AI-driven approaches can be continuously tested, calibrated, and scaled based on human feedback.
Encoding Processes to Power Automation
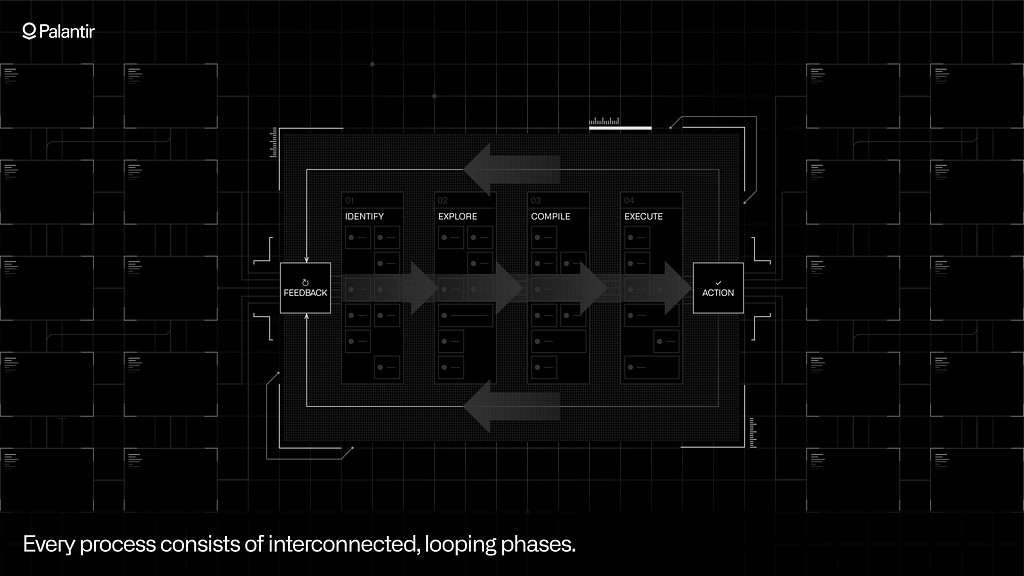
A process can only be automated if it is encoded in software.
For a given process, there are phases that involve identifying which tasks require attention — often in situations where there are competing priorities. These feed into more exploratory phases, where different possible courses of action are assessed. Sometimes the ‘decision space’ being explored is governed by a rigid, rules-based model, while in more complex cases, it might involve a blend of multi-step simulations and human judgment. The chosen decision then typically needs to be ‘compiled’ in some manner; i.e., the course of action needs to be verified, given the constraints of the business and the approvals and checkpoints that might be in place.
The final phase is the actual execution of the decision; this can involve updating transactional systems, publishing events to edge systems, or orchestrating a piece of operational logic that drives a production controller or machine on a factory floor. This execution updates the state of the world, which then feeds into the next loop through the process.
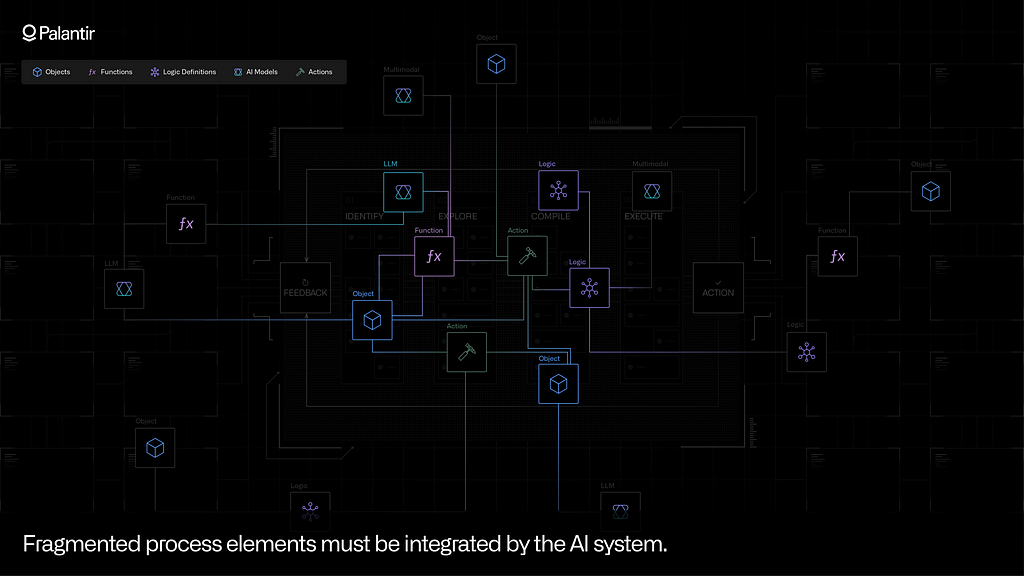
Many of the elements that make up these process phases are found across disconnected systems.
Disparate data systems contain structured data, streaming data, media files, documents, and other pieces of information that — when properly integrated — provide the context needed by those who are carrying out critical workflows. This means that the AI system needs a full-spectrum approach to data integration, which can fuse all types of data, from any source, into a common model of the operational world. Tooling for virtualizing existing data, monitoring the health of data pipelines, and enforcing granular security policies must work across all types of data, at any scale.
Critically, a process is defined by more than data. Logic sources, such as systems containing business rules, machine learning workbenches containing forecasting models, and solvers that run optimizations, provide the elements for powering exploratory reasoning and scenario analysis. Encoding the relevant logic assets into a shared model of the process can mean importing existing code as containers; shifting existing codebases into secure, elastic infrastructure; or dynamically calling these pieces of logic through APIs.
Last but not least, the actions — every ‘verb’ that is paired with every ‘noun’ — must be encoded. This means tracking the inputs into every action that is taken, the different pathways that are evaluated during the reasoning phases, and the consequences of executing the action, including feedback and learning. Concretely, this means the AI system must integrate with the enterprise’s fragmented systems of action (e.g., ERP systems, MES systems, PLMs, edge controllers), and must maintain a durable record of the actions orchestrated across environments.
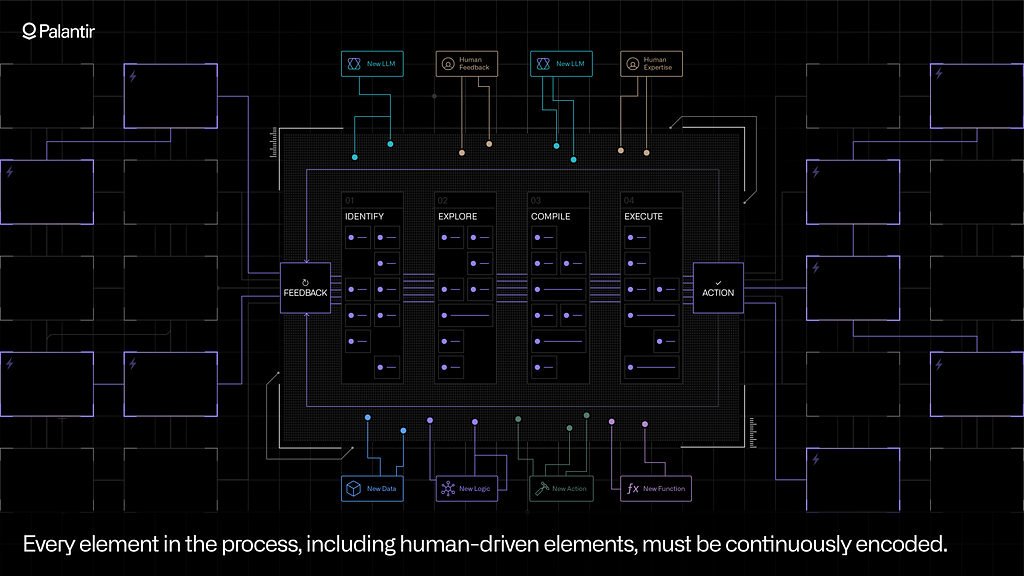
While most operational processes have a blend of elements that can be sourced from different digital systems, they often also have critical elements that are not encoded anywhere but in the minds of operational users.
Hospital staff do not schedule patients by looking at rigid tables in the EMR systems or abiding by a rules engine; those things are inputs of course — but ultimately the decision maker draws from experience, after weighing several options that are partially represented across systems. In automotive manufacturing, timely and integrated data can help quality engineers properly categorize issues and identify which investigations to conduct; but ultimately, the data and algorithmic techniques feed a broader process, which is anchored in the engineer’s operational experience.
The AI system must enable the best-effort, continuous encoding of these human-driven parts of the process. This means providing flexible application building tools that enable human users to weave into workflows that are starting with minimal or partial automation, which can organically evolve over time. It can also mean leveraging Generative AI to capture the context and reasoning involved in human-driven tasks, which have historically been sequestered within documents, images, videos, and audio files.
Levels of Automation
The continuous encoding of operational processes allows AI-powered automation to steadily expand in scope and learn from frontline feedback. Every process where humans and AI are working together becomes a rich canvas for learning. Where did the operator hand off to the AI? Where did the AI make a sensible recommendation? Where did it not?
Human preferences — captured through scenarios being evaluated and actions being taken — form a stream of ‘tribal knowledge’ that can be fed into every AI-powered component of the decision-making process. Over time, this distills the business acumen that’s been limited to certain individuals, combines it with the vast amount of operational context that AI can leverage, and scales it through the resulting automation.
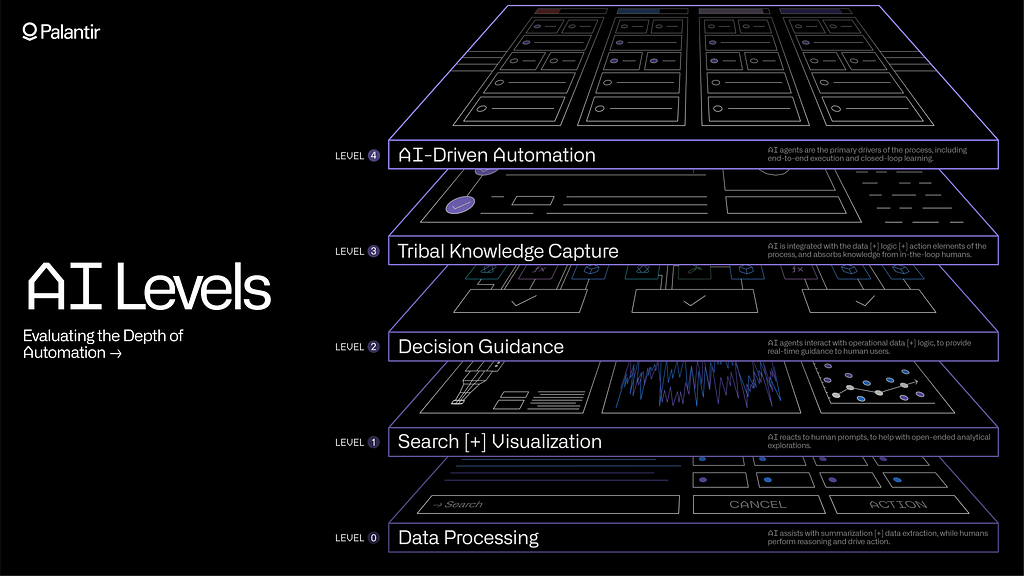
Palantir uses the AI Levels framework to assess the depth of automation, within a given operational process. In short:
Level 0 involves basic and secure access to LLMs; where the models are helping with summarization or data extraction — but ultimately so that human users can continue to reason and act themselves.
Level 1 takes this one step further, with secure data integration, and the ability to conduct both search and visualization workflows. Level 1 tasks often involve AI reacting to prompts, to aid with open-ended exploration.
Level 2 is where AI begins to interact with both data and logic, to provide decision guidance. This can involve agents using tools to run simulations and other calculations, to guide human users as they work in real time.
Level 3 is reached when Generative AI is integrated with the data, logic, and action elements of the process. Agents are deployed across entire workflows, and they are absorbing the tribal knowledge from humans who remain in the loop.
Level 4 is defined by agents taking the primary role in a process; humans may still provide oversight and feedback but the end-to-end executions, learning, and improvement loops are now AI-driven.
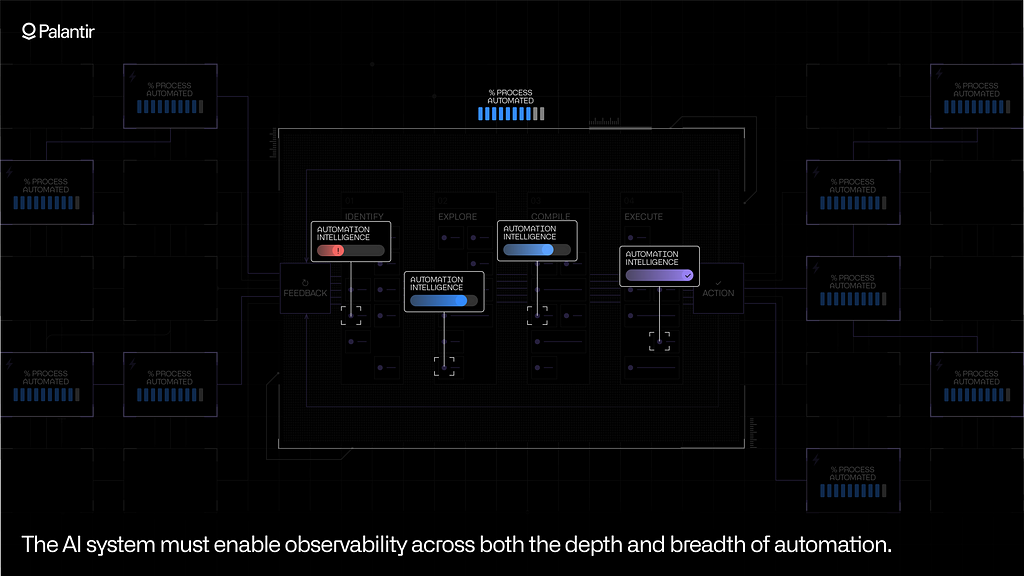
These levels of depth are complemented by a holistic measure of breadth; i.e., how many enterprise processes are being infused with AI — and what is the compound effect? One dimension of breadth is simply coverage within the operational space. How many of the processes that constitute the fulfillment workflow in the supply chain are automated? How many of the workflows across customer service are automated? To what degree?
The other dimension is connectivity; where is the infusion of AI enabling the elimination of the artificial walls between processes? To what degree has AI-driven automation redrawn the rigid lines and enabled the enterprise to better connect strategy with operations?
The Cybernetic Enterprise
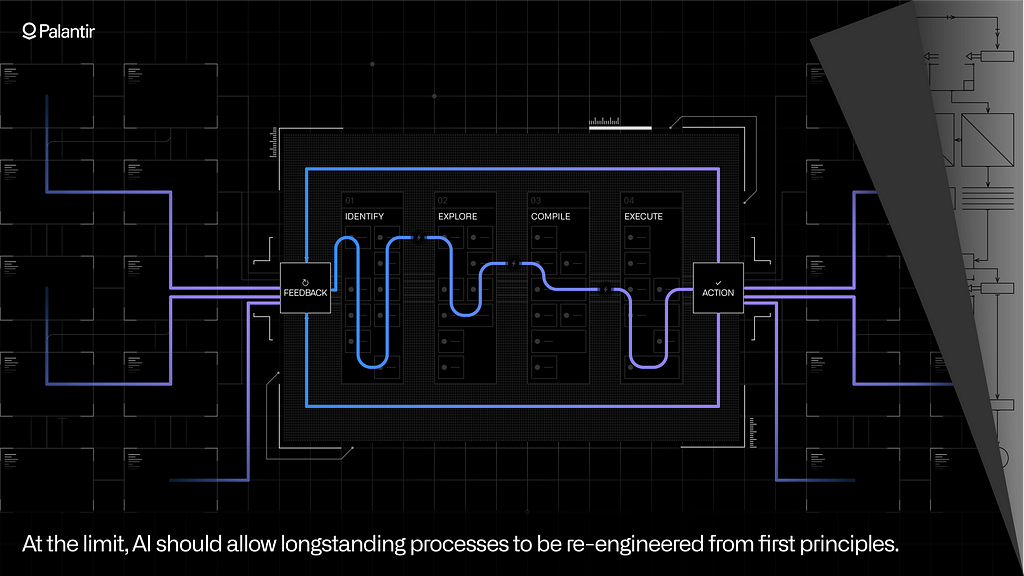
At the limit, AI should allow longstanding processes to be re-engineered from first principles. Workflows that have traditionally been spread across disjoint teams can be integrated into continuous single processes, and can be measured against KPIs that more authentically reflect operational outcomes. As exogenous conditions change, and internal goals continue to evolve, the enterprise should be able to encode new strategic objectives and have them seamlessly update all nested operational goals.
The role of the operational user evolves as well, as the breadth and depth of AI expand. As agents manage steadily more end-to-end processes, human users gain increasing operational leverage. Their roles shift from being purely execution-centric to instead managing fleets of agents — and overseeing the integration of the feedback-based learning that is now being processed at machine speed.
This is emblematic of true operational steering — the “cybernetic enterprise,” which was the original goal of Silicon Valley and the computing revolution.
For the AI revolution to be a worthy one, it must be driven through open, extensible architectures that break from the shackles of the Software Industrial Complex.
This means that every component of a process that is integrated from digital sources — data systems, logic sources, systems of action — must be represented as building blocks that can drive AI-enabled application building both inside and outside of the platform, through robust APIs and SDKs. It also means that the system must abide by open standards, and enable flexibility. Every data element should be stored in non-proprietary formats; a range of open compute engines should be made available; there must be flexibility in how models can be developed, stored, and orchestrated — in adherence with open standards.
The platform must provide compounding leverage for AI developers as each new application is delivered. Every data integration must produce a reusable artifact which can be automated; every piece of business logic must become a scalable tool for both human and AI usage; and every user interface component must allow for human-driven action to smoothly transition to human-AI teaming, and then to end-to-end automation. Developers should also not be constrained by a particular environment or framework; the platform should provide a secure, modular development environment which can be seamlessly integrated with common coding environments and DevOps toolchains.

Taken together, these requirements describe the need for a very different system architecture. Trying to extend traditional data or analytics architectures might work for simple retrieval-oriented workflows like RAG, but building AI-driven automations requires a technical foundation that is fundamentally process-centric, not data-centric. Loops, rather than linear tabulations and BI reports.
Everything from the multimodal data architecture, to the interoperable model architecture, to the real-time workflow architecture, to the underlying security architecture — must be geared towards infusing AI throughout core operational processes, removing the latency between strategic shifts and operational action, and enabling the enterprise to optimally execute its essential mission.
The Cybernetic Enterprise was originally published in Palantir Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
API Versioning At Gusto

Introduction
Just over two years ago, we introduced date-based versioning to the Gusto API. Since then, we’ve released over ten(!) versions of our public API. And over the past half year, our engineering and technical solutions teams have collaborated closely with our partners to deprecate our ten oldest versions, migrating the majority of our integrations to leverage our latest stable API versions — the most performant, secure, and developer-friendly evolution of our API.
In the changing landscape of payroll and compliance, especially at scale, we future-proof our API by versioning it.
In this post, we’ll share more about our API versioning approach, how we continue to operate this change management process, and most importantly, the lessons we’ve learned along the way.
What is API versioning?
If you’re already familiar with API versioning, feel free to skip below to “Lessons learned: A debug log.”
An API represents a contractual exchange of data between a provider and client. Given a specific interface, our partners expect to be able to create, update, and retrieve data in a mutually agreed-upon interface.
Contracts shouldn’t change unexpectedly. When developers integrate with our API, they write code with expectations built into it. Changes that break these assumptions can also break developer integrations; for example, if we suddenly remove a response field or make a request parameter required, our partners’ applications may unexpectedly error. As a critical piece of infrastructure for our partners, this is our worst-case scenario.
Sometimes, implementing breaking changes is necessary for the security, performance, and usability of an API. When we decide to roll out such changes, we encapsulate them into a new API version — much like a new product release. When a new version is released, it has no impact on an existing integration until a partner choose to upgrade their application to use the latest version.
Not all changes are breaking changes. Non-breaking changes can be backported to older API versions and do not impact an existing integration in a disruptive manner. Currently, we release these types of changes to production immediately (with typically no version upgrade required). This offers our existing partners an opportunity to improve their embedded payroll product or integration at their pace.
Both types of changes are always published to our API changelog upon release. You can read more about our latest API versioning policy in our API version guide.
Life of (an A)PI
Incremental system upgrades are common practice; if you’re a developer, you might be familiar with routine major and minor version releases from your language of choice, which may bundle together critical bug fixes, syntax updates, and removed features. A similar mental model: if you’re an iPhone user, you might also receive push notifications when a new iOS version is available and ready to be installed that night.
We’re cognizant that upgrading an API version doesn’t auto-magically happen overnight (and certainly not while you’re asleep — though one can dream!). A new version is a disruptive event in the lifecycle of an API. For an API consumer, it means that they must, at some point, allocate engineering resources to upgrade their integrations. Therefore, each version release results in the accrual of tech debt.
Our utmost priority is to provide a frictionless developer experience for our Gusto partner developers, whether they are building payroll software integrations or an embedded payroll experience. Figuring out how to gracefully introduce, manage, and deprecate an API version is perhaps one of the most significant challenges to this mission statement (credit is due to one simple, sneaky truth: change is hard). To help manage change internally, we’ve explicitly defined the lifecycle of an API into the following phases:
- Beta
- Stable
- Deprecated
- Sunsetted
- Retired

We may offer early or beta access to an API version, particularly if the included changes are at the top of the wishlist for partners. Once the version has passed our internal QA — during which we also dogfood the new version with our own API consumers, like Gusto Embedded Flows — it can then be stabilized, and ready for general public consumption.
Deprecated and sunsetted may sound like interchangeable statuses, but represent different stages of an API version’s end-of-service life.
When a Gusto API version is marked deprecated, we are actively suggesting that you stop using it; this may be due to existing security vulnerabilities, incompatibility with newer API versions, and/or new compliance requirements.
During the deprecation period of an API version, we tag this version as “Deprecated” in our public API docs. To ensure that our partners are notified and can plan ahead for version upgrades in their roadmap, we also dispatch extensive deprecation notices via a variety of channels: changelog posts, direct email outreach, dashboard alerts in your Developer Portal account, and API response headers.
A final sunsetted date is served with these deprecation notices. After the sunset date, requests made to that version will begin to fail with a 406 Not Acceptable error. Note that when a version has passed its sunset date, we will remove public guidance and API documentation for that version.
Finally, when there are no longer any active consumers of an API version, we can officially retire the version and begin versioned code removal from our end. The benefits here are two-fold: our API consumers can reap the benefits of a more performant, secure, and usable API. On our end, we’re able to reduce our version maintenance overhead and clean up tech debt from our systems.
Lessons learned: A debug log
As we’ve rolled with the (breaking) changes in the past two years, we’ve gathered some insights on effective API versioning along the way.
Just as the best things in life are free, the best changes to an API are ones that aren’t breaking
In some cases, implementing a breaking change can be avoided in lieu of implementing a non-breaking one instead. We carefully evaluate whether a breaking change necessitates a whole new API version, and whether it’s possible to achieve the desired outcome without breaking the existing contract.*
*It’s worth caveating that this isn’t a universally applicable principle; making additive, non-breaking changes can run the risk of increasing the complexity of an API, which can in turn worsen developer ergonomics. Moreover, some API changes are widespread by nature; for example, in a previous API version 2022–11–01, we removed support for IDs (in favor of UUIDs) in request parameters and response attributes.
Each API version should represent a meaningful unit of change
When versioning for our API was introduced, we were (admittedly) overzealous about using it. While some of our now-sunsetted API versions encapsulated large system-wide updates, others contained small changes impacting a singular API. This resulted in the quick production of 10+ versions, ranging from major updates to minor tweaks.
For our partners using our oldest version, we empathize that upgrading a double-digit number of API versions can sound daunting. Going forward, we intend to group breaking changes into more meaningful units of change, so that each new API version represents a significant upgrade from the previous one.
Our first goal is to avoid making a new API version in the first place, but when an API version is absolutely necessary, our next goal is to make it well-scoped.
Opt into documentation-driven API design
We do our best to get our API design right the first time around. At Gusto Embedded, we practice documentation-driven design to help drive the construction of intuitive APIs.
The actual practice of documentation-driven design (DDD) varies from company to company; we tend to shave it down to: “If a feature is not documented, then it doesn’t exist, and if a feature is documented incorrectly, then it’s broken” (source). Before we build an API, we are intentional about how it looks and feels to a developer who leverages it.
The world of payroll, taxes, and compliance is complex. Our job here is to simplify and abstract it intuitively. Writing a documentation-driven spec before implementation helps us achieve this in our API design. When we contextualize an API design in its problem space, we learn about unknown unknowns and can quickly validate our assumptions with non-technical domain experts.
Occasionally, we share these documents externally with partners for preview and early feedback. This further tightens our feedback loop and helps us avoid fixing costly errors or inconsistencies down the line.
Make version management as cost-effective as possible
Versioning improves the developer experience by offering stable and long-term support for an API. At the same time, we’ve learned that maintaining many API versions can result in compounding internal maintenance costs over time:
- Increased code bloat
- Increased cognitive load (context switching depending on the API version)
- Increased code duplication, especially across an automated test suite
To manage our own maintenance burden, we refined our change management process such that when an API version moves to a new stage of its lifecycle (e.g. stable to deprecated), we incur only a consistent, fixed overhead.
We accomplished this in a few ways. For one, we created a prescriptive, self-validating Domain Service Language (DSL) in Ruby. Because each version’s logic is neatly encapsulated inside its respective block, this makes it easy to contribute, contextualize and eventually cut out the version (on retirement) without impacting other parts of the code.
# GET /employees/:employee_id
def show
api_versions do |version|
version.v2025_01_01 do
render json: { name: name } # no longer includes the `foo` field
end
version.vbase do
render json: { name: name, foo: :bar }
end
end
end
Additionally, we maintain a robust automated pipeline that helps us propagate breaking and non-breaking changes to our API reference, updating all versioned documentation (as well as our public Postman collections) from a single source. Write once, update many.
Communicate, communicate, communicate
Communication is crucial when an API version enters the deprecation process. To ensure partners are well-informed of changes, we send out multi-channel comms as a version enters its deprecation period. We offer and maintain a version upgrade guide to help partners allocate time for upgrades in their roadmaps. We believe that clear self-serve documentation helps encourage proactive (rather than reactive) adoption of new versions.
If possible, our team may automatically upgrade partners’ demo applications to next stable API version. If we cannot automatically upgrade an application, our partners can expect to receive communication from our Gusto Developer Relations team (developer@gusto.com) on next steps.
We recognize that each of our partners has unique business needs, distinct API requirements, and changing product roadmaps. As a critical piece of infra for our partners, our north star is to make our API updates as seamless and straightforward as possible, so that our partners can focus their time on scaling their own businesses.
If you’d like to build with our API, head over to our Developer Portal to get started.
Interested in working with us on building a best-in-class developer platform? We’re hiring!
API Versioning at Gusto was originally published in Gusto Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.
Written by Shima Nassiri and Ido Bright

Network Effect
At Lyft, we run various randomized experiments to tackle different measurement needs. User-split experiments account for 90% of the randomized studies due to the higher power and fit for most use cases. However, they are prone to interference or network bias. In a multi-sided marketplace, there is no such thing as a perfect balance of supply and demand and one side of the market is congested: if we have oversupply, we can run rider-split experiments without interference concerns. If we are undersupplied, however, interference in a rider-split experiment can severely bias the results. Same goes for under or over-demand situations and driver-split experiments. For example, in a supply constrained situation, not enough drivers are available to address the demand. As illustrated in Figure 1, in such an environment, if the treatment in an A/B experiment incentivises higher convergence of riders to complete their intended rides, there will be fewer resources available for the riders in the control group. Hence, the outcomes of the control group will be negatively impacted by the treatment through the congested resource (i.e., the drivers) and the impact of treatment can be overestimated — this is known as interference bias or network effect. This situation violates the Stable Unit Treatment Value Assumption (SUTVA) which indicates that the control group should not be affected by the treatment to keep the results unbiased.
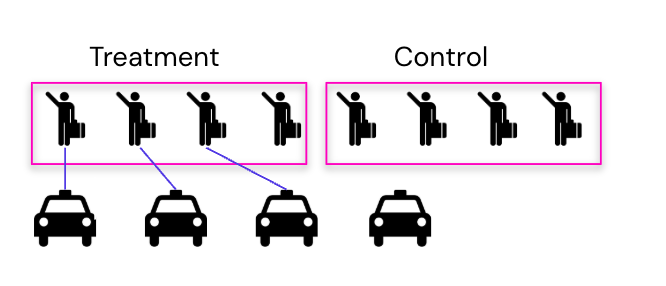
It’s important to recognize that interference doesn’t always lead to an overestimation of the treatment effect. For instance, in social networks, treating units in the treatment group can positively influence the outcomes for control units who are friends with those treated, boosting control outcomes and thus reducing the perceived treatment effect. Similarly, in a retail setting, with complementary products, treating units in the treatment group might positively impact complementary products often purchased together, inflating control outcomes and underestimating the treatment effect. Conversely, for substitutable products, the opposite occurs, where the treatment effect may be overestimated.
Possible Solutions to Interference
Much of the literature on interference focuses on modifying classical experimental designs to mitigate its effects. Cluster randomization is a popular method for addressing interference. For instance, at Amazon, cluster randomization is explored to tackle interference issues among substitutable products. In Section 4 of Cooperider and Nassiri (2023), the authors also address the challenge of low power resulting from such clustering and discuss how power can be improved through better cluster balancing.
Other alternative designs like time-split or region-split experiments can also be used to address interference. In a time-split experiment all units are exposed to a single treatment at any given time or time-location combination, which helps prevent the interference effect. (This type of experiment is also known as switchback). However, this approach can affect the user experience for user-facing changes. For example, if we frequently toggle a UI feature that provides the driver with more rider information, it might disrupt the user experience. Additionally, time-split experiments are inherently suited for scenarios where the focus is on the overall marketplace impact. They are designed to capture short-term marketplace behavior, as users experience different treatments throughout the experiment. However, it’s not possible to include a holdout group in a time-split experiment, making them unsuitable for assessing long-term impacts. Therefore, time-split experiments are suitable only for a limited range of use cases. Experimenters might opt to run a combination of a time-split experiment followed by a user-split experiment to leverage the strengths of both approaches. This strategy allows them to accurately gauge marketplace-level effects without interference concerns through the time-split, while also assessing user-level, long-term impacts via the user-split. However, this approach is costly to implement and can delay decision making by several weeks.
On the other hand, region-split or geo experiments apply a treatment across an entire region or region-time bucket, effectively eliminating interference bias since significant interference across different regions is unlikely. Additionally, they don’t impact user experience. However, region-split experiments often suffer from low statistical power due to smaller effective sample sizes, which limits their large-scale adoption.
Another method to obtain unbiased treatment effect estimates despite interference is by modeling interference. Interference can be a challenge in two types of marketplaces: choice-based (e.g., Airbnb and Amazon) and match-based (e.g., Lyft and Doordash). In choice-based marketplaces, customers select from multiple options, making it more complex to model the interference. In contrast, match-based marketplaces assign customers to a single option, which simplifies the modeling of interference. At Lyft, we use a Marketplace Marginal Values (MMV) approach for modeling interference. You can find the theoretical details of this approach in Bright et al. (2024). Essentially, MMV represents the change in the gain (which can be whatever you are optimizing for, e.g., more profit or rides) as a result of changing the resource (additional supply/demand) by one unit. This concept is commonly known as the shadow price in the operations research literature.
Why MMV?
In the paper, the authors present technical proofs demonstrating how marginal values can help significantly reduce the estimator bias of the treatment effect. Essentially, the primary source of interference bias as previously mentioned, is the competition for limited resources. Marginal values effectively capture this resource contention. Consider the following situations:
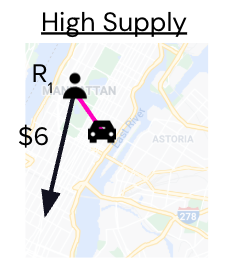
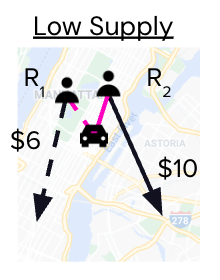
As illustrated in Figure 2, when supply is abundant, the marginal value of having rider R1 matches its face value, which is $6. However, in a low supply scenario where resources are limited, the resource is allocated to rider R2. Consequently, both the marginal and face values for R1 become zero. For rider R2, the face value is $10, but its marginal value is only the additional $4 gained by having rider R2. This demonstrates how the marginal value inherently accounts for resource contention. By aggregating the marginal values across both the treatment and control groups and calculating the difference, one can derive an unbiased estimator of the average treatment effect.
How to compute MMVs?
As previously mentioned, shadow prices in the dispatch optimization problem can be used to obtain the MMVs. The primal dispatch problem can be described as follows:
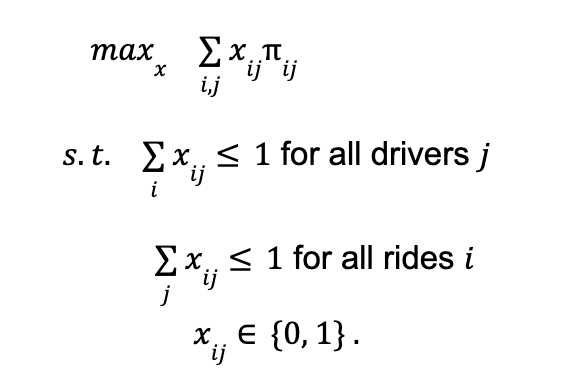
Where xᵢⱼ is a variable that takes the value of 1 if the driver j got matched to that rider i, and 0 otherwise. πᵢⱼ represents the score (e.g., profit) of matching driver j to rider i. The first constraint ensures that a driver is matched with at most one ride per a matching cycle (more on this later), and the second constraint indicates that a rider can have at most one driver. Solving this optimization gives the optimal matching of drivers to riders. We can relax the last constraint into xᵢⱼ ≥ 0, and obtain a linear relaxation of the above problem for which we can compute the dual as:
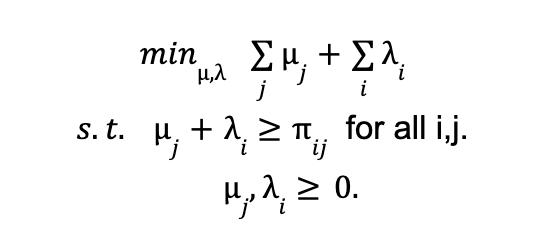
The dual variable μⱼ is associated to the driver constraint (first primal constraint), and λᵢ is associated with the rider constraint. This means that for each driver j, there is an associated dual variable μⱼ (same is true for riders). More on duality can be found here. To find the MMV values, we aim at generating a matching cycle dispatch graph, solve it, and then efficiently compute the incremental values via the duals. Consider the objective function, denoted as Π(d,s), where d and s represent the demand and supply respectively. Assume that the treatment effect results in increasing the demand by e. Then the global effect of such treatment can be presented as follows:
Now to estimate Δ, we can do a rider-split 50/50 A/B test where each group serves half the demand. Consider the demand in each group being presented by dₑ. We then have
The global average treatment effect can then be estimated as:
where λ* is the optimal rider dual or shadow price. Here, the analysis provides the first order Taylor approximation results — for more details see Proposition 5 of Bright et al. (2024). We can observe that the difference in the objective function outcomes across treatment and control groups can be presented by the shadow price. In the paper, the authors further did a simulation and showed this shadow price estimator will hamper the overestimation of the default estimates from standard A/B tests while lowering the noise level (refer to Figure 8 in Bright et al. (2024)).
Matching Cycle
Next, we need to decide how often to solve these optimization problems, essentially determining the length of the matching cycle. If the matching cycle is too short, contention can occur between cycles. For instance, a driver who isn’t matched in Cycle 1 might be available in the next cycle, or a rider choosing the wait-and-save option might wait several cycles before being matched. At Lyft, we use a 1-hour mega cycle to solve the dispatch optimization problem for all eligible riders and drivers within that period. This cycle length helps significantly reduce concerns about contention between cycles.
Secondary Metrics
Finally, if we want to assess the MMV-corrected impact of a treatment on metrics beyond those defined by the dispatch objective function, we can compute the edge or ride cost for each completed ride (e.g., νᵢⱼ). Considering a linear relaxation of the primal problem and applying complementary slackness, we have:
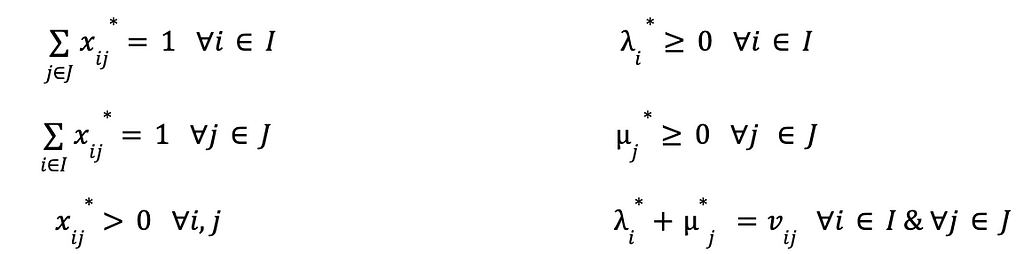
Assuming non-degeneracy, we can then solve the above system of equations to find the optimal dual values and use them to estimate the average treatment effect same as before.
Productionalizing MMV in an Experimentation Platform
To implement MMV in an experimentation platform, we solve the matching optimization problem for passenger and driver duals on an hourly basis, as previously described, and store these values in a table. This data is then used to calculate MMV-corrected values for drivers and riders. These metrics are included in experiment reports alongside other metrics, with standard computations like CUPED applied to them. Below is an example of how an MMV-corrected metric might appear in a driver randomized experiment. Here, riders are the congested resource contributing to the interference bias, and over-estimation of the results as discussed earlier. The MMV correction would hamper the effect by accounting for the contention over the limited resource (in this case pool of riders).

It’s important to note that there are limitations to the use cases for MMV. For instance, MMV cannot be applied in situations where the target population for randomization is not drivers or passengers. An example of this would be mapping experiments where the route is associated with the ride itself, rather than being specific to drivers or passengers, making MMV-corrected metrics unsuitable.
MMVs in Practice
Other experimental designs like time-split, region-split, or a combination of time- and user-splits often fall short in addressing the majority of experimentation needs. They tend to lack sufficient power, are costly to implement, and can take several weeks to execute. In contrast, the MMV approach can adjust the effect sizes in user-split experiments where interference is a concern. This is particularly important in cases with significant network effects, as the change in effect magnitude can be substantial, potentially altering launch decisions under MMV correction.
At Lyft, we’ve had instances where both time- and user-split experiments were conducted for the same initiative to capture both market-level and long-term effects. We compared the MMV-corrected user-split outcomes with the time-split outcomes in three historical cases where a time-split counterpart was available. After applying MMV correction, we observed greater alignment with the time-split results.
Additionally, a comprehensive backtest across various user-split experiments was conducted, comparing MMV-corrected completed rides with traditional metrics. In 10% of these comparisons, the launch decision could change when using MMV-corrected values. These cases were evenly split between false positives (launching based on traditional values when MMV-corrected values didn’t meet launch criteria) and false negatives.
Moreover, when MMV results show a lower magnitude compared to naive user-split results, particularly in resource-constrained experiments, we anticipate an average 45% reduction in outcome magnitude based on this numerical study. This decrease occurs because the contribution of each ride is divided between the rider and the driver when calculating marginal values, thus correcting for the overestimation of effects due to interference bias.
Acknowledgements
We would like to thank Anahita Hassanzadeh and Thu Le for helpful discussions and suggestions.
Lyft is hiring! If you’re passionate about experimentation and measurement, visit Lyft Careers to see our openings.
Using Marketplace Marginal Values to Address Interference Bias was originally published in Lyft Engineering on Medium, where people are continuing the conversation by highlighting and responding to this story.