Instacart
Optimizing search relevance at Instacart using hybrid retrieval
2024-9-11
Vinesh Gudla

Vinesh Gudla, Prakash Putta, Ankit Mittal, Andrew Tanner, Tejaswi Tenneti
Introduction
Search is a critical component of e-commerce platforms especially at Instacart where it drives significant customer engagement on the platform. A critical component of any search engine is the recall layer which is used to retrieve the relevant documents for a given search query.
Recall in modern search stacks is driven primarily by two methods: text search and semantic (or embedding) search. Each method has its strengths when retrieving relevant documents: text search excels at keyword matching between query and document while semantic search shines at understanding the query context and intent. Typically, recall sets are constructed by independently fetching documents from each method and then independently merging the results.
While this approach scales well, it is generally suboptimal. In this blog post, we will explore the limitations of the current system and discuss how we built a hybrid search architecture that leveraged the concept of query entropy to jointly optimize the recall set generation across the different retrieval mechanisms. In a follow-up blog post, we will go into how we migrated to pgvector and the infrastructural changes we made to enable this architecture.
First let’s start with an overview of the current search retrieval architecture at Instacart and some of the challenges we face.
Search retrieval at Instacart
Instacart is a four-sided marketplace with multiple retailers across a wide range of verticals featured on the platform. As of Q4’ 2023, Instacart’s catalog had over 1.4 billion documents (items) served across 1500+ national, local and regional retailers. While these numbers are not massive at today’s ecommerce search scale, there are a number of challenges faced by the search retrieval layer due to the nature of the Instacart marketplace as discussed below.
Challenges
Variability in query distribution
The vast array of retailers leads to significant variance in search query distribution and the number of relevant documents per query. For instance, the query “tofu” yields over 100 results at 99 Ranch Market (retailer specializing in Asian groceries) but fewer than five at Costco, due to differing retailer offerings across locations. The query’s specificity also impacts the retrieval effectiveness, with text search suiting specific queries and semantic search aiding understanding in ambiguous cases.
Over-fetching of documents
Operating text and semantic retrieval mechanisms independently often results in a fixed number of items being retrieved from each source, regardless of the query or retailer. This approach is not only wasteful but also reduces precision, particularly when there are limited relevant items for a query.
Recall Architecture
In order to handle the above challenges, over the years, we tuned the two retrieval mechanisms independently to improve recall performance. Let’s dive deeper into each of these systems to understand the limitations with this approach.
Text Retrieval with Postgres
For text retrieval, we rely on Postgres and SQL queries are used to fetch relevant documents based on the query context.
- Indexing: Documents are indexed using GIN indexes.
- Scoring: A customized term-frequency algorithm (ts_rank) scores documents based on their relevance to the query.
- Retrieval: The top Kt documents are fetched from Postgres based on these scores.
Semantic Retrieval with FAISS
For semantic retrieval, we use an approximate-nearest neighbor (ANN) search service built using Facebook’s FAISS library. This method operates on vector embeddings, enabling efficient searches through vast document spaces with minimal recall accuracy tradeoff
- Embeddings Generation: We use a bi-encoder model based on the Huggingface MiniLM-L3-v2 architecture to generate query and document embeddings. For more details on our embedding training and usage in search, you can refer to our detailed blogpost on embeddings.
- Indexing: Document embeddings are indexed using FAISS.
- ANN Search: At runtime, the query embedding is passed to the ANN service. The top Ke relevant documents are then returned, ranked by the dot product scores of the query and document embeddings.
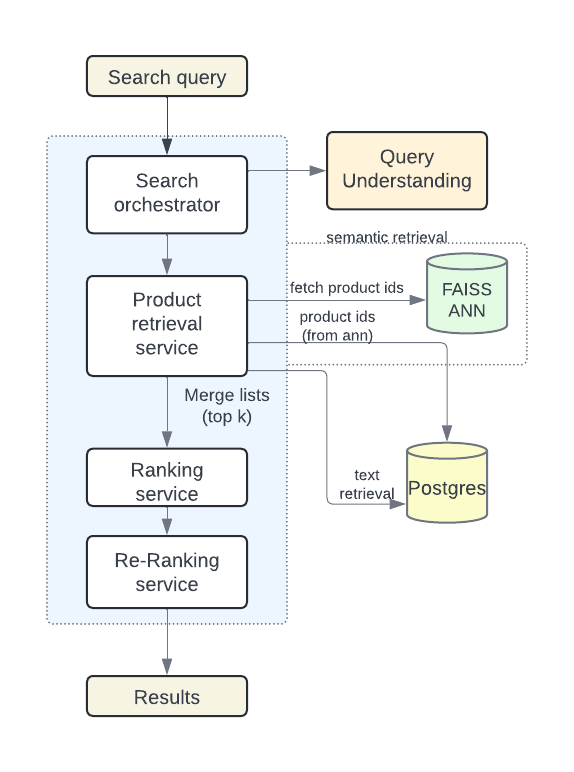
At runtime, we make parallel requests to each of these indexes to retrieve the top relevant documents from each index. The top Ke retrieved documents from the semantic index are merged with the top Kt documents retrieved from the text index. The top K relevant products after merging these two lists are then passed down to the downstream ranking stages (Fig. 1).
recall set = top K [{Kt documents from text retrieval} ∪ {Ke documents from semantic retrieval}]
Towards Adaptive Retrieval: Combining Text and Semantic Searches
Our initial approach generated a fixed-size list of documents from each retrieval mechanism, without considering the specifics of each query. This naive merging and filtering method often proved suboptimal, as one retrieval mechanism might be better suited for a particular query. To enhance both recall and precision, we recognized the need to adapt the recall set contextually, based on the query and the retailer.
Adaptive Recall Model:
As a first step towards a more optimal retrieval strategy, we decided to build a model that would allow us to adaptively tune the recall set size from each retrieval mechanism based on the request context i.e. the query, retailer. To adaptively construct the ideal recall set, we turned to a query specificity model called query entropy.
Query Entropy
Query entropy measures the specificity of a query and models the variation or uncertainty in the number of relevant documents for that query.
query_entropy = -Σ P(doc_id | query) log₂P(doc_id | query)
where P(doc_id | query) = count(doc_id converted | query ) / count(query) and the sum is over all doc_ids retrieved for that query
Using query entropy allows our system to dynamically adjust the retrieval approach:
- For highly specific queries like “lucerne 2% low-fat milk”, the query entropy is low, indicating a small number of relevant results.
- For broader queries like “snacks,” the query entropy is higher indicating a larger number of relevant items and consequently a larger recall set.
To illustrate this concept better, Fig. 2 shows how the mean converting position (display position on the page at which a search ends in a purchase) varies as a function of query entropy.
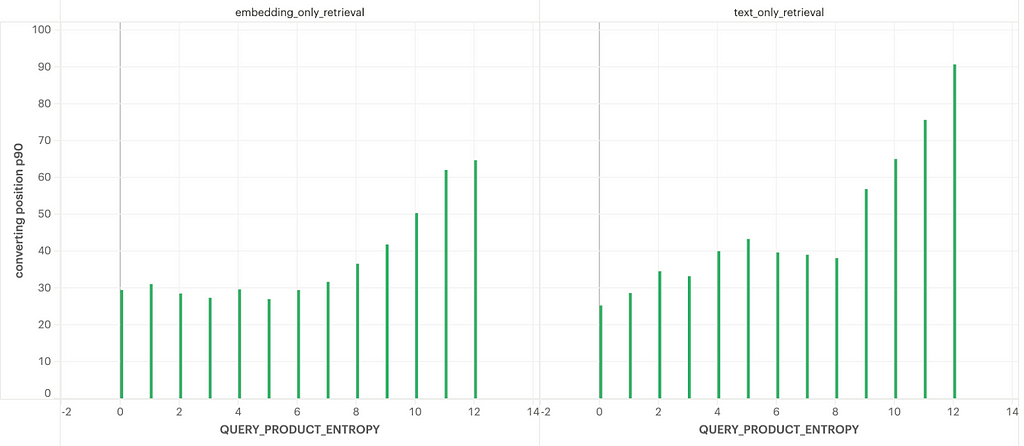
For higher entropy, the number of relevant results is higher and so users tend to scroll down more which results in a bigger mean converting position as entropy increases.
More importantly, the ratio of relevant items between text and embedding retrieval also varies by entropy, allowing us to adaptively determine the recall set size for each recall type based on the entropy.
Adaptive recall set sizes
Using the knowledge that the recall set size can be tuned as a function of the query entropy and recall type, we were able to tune the recall set size adaptively across different retailers and queries. This helped us to have a more relevant final recall set and also minimize the over-fetching problem. The recall threshold for each retrieval mechanism is determined using the equation below:
recall_threshold = min(M, max(L, M * query_product_entropy / Q))
where
- L is the minimum number of products to recall.
- M is the maximum number of products to recall.
- Q is the value to which we clip query product entropy.
- query_product_entropy is the calculated entropy for the specific query.
Fig 3 illustrates how the recall set size adapts as a function of entropy, with L=500, M=1000, and Q=10.
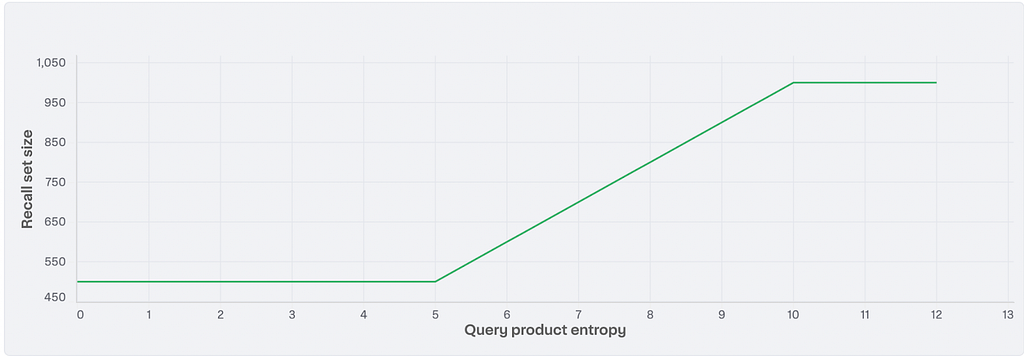
To adaptively construct the ideal recall set, we follow these steps:
- Calculate Query Entropy: Determine the entropy value for the current query.
- Adjust Recall Thresholds: Adjust the recall thresholds for text and semantic retrieval mechanisms based on the calculated entropy.
- Retrieve and Combine Results: Fetch the documents from both retrieval mechanisms and combine them contextually to create a more relevant recall set.
This adaptable approach optimizes the recall set distribution, improving relevance and reducing latency. It represents a significant step towards a more intelligent and efficient retrieval strategy, as reflected in improved search metrics such as mean converting position by 1.7% and reduced latency by 1.5%.
Towards hybrid search
While adjusting the recall set sizes based on the query and retrieval mechanism significantly improved recall set distribution and latency, there is more potential for enhancement. To further boost recall performance, we are working on merging the recall sets in a more integrated manner. This effort is a work in progress, and we will highlight some of the approaches we are currently exploring for generating optimal recall sets.
Hybrid retrieval
A fusion approach to merge the retrieval sets is the norm in current industry hybrid search architectures and a number of datastores have some built-in support for this. The method used to merge the recall sets can vary depending on whether the datastore supports traditional text matching algorithms like BM25 or sparse vectors. For example, Pinecone and Qdrant support hybrid retrieval of sparse and dense vectors while others like LanceDB support a customized retrieval function that combines semantic and text match scores.
In our platform, we are exploring a few different approaches of which a couple are listed below:
Reciprocal Rank Fusion (RRF):
- This non-parametric approach combines ranked lists with different ranking criteria.
- The algorithm merges the lists using the reciprocal of the ranks of products.
- For instance, if a product is ranked x in one list and y in another, its combined score is calculated as (1/x + 1/y). These combined scores are then used to generate the final ranked list.
Convex Combination of scores:
- This method uses a weighted combination of lexical and semantic scores for each product.
- We compute global weights, w1 and w2, which determine the emphasis on each retrieval mechanism (lexical and semantic).
- The weights can be adjusted based on the query and retailer context to further refine the recall.
- The combined score for a product is calculated using the formula:
document_score = w1 * lex_score + w2 * sem_score
Key takeaways from our efforts:
In our journey to enhance the search experience on Instacart, we have embarked on the path towards a truly hybrid recall architecture that intelligently combines the strengths of text-based retrieval with those of semantic (embedding) search. This initial step allows us to overcome significant challenges such as varying query distributions, retailer-specific item variations, and the inefficiencies of over-fetching documents.
Adaptive Recall:
- By leveraging query entropy, we have developed an adaptive system that tailors the recall sets based on the specificity of user queries.
- This approach optimizes search relevance and minimizes over-fetching which lead to improvements in search metrics.
Towards a Fully Hybrid Search:
- Our current work lays the foundation for a more optimal recall set generation.
- Techniques such as Reciprocal Rank Fusion and Convex Combination of scores are set to further enhance the precision and relevance of the recall sets.
Infrastructure Improvements:
- We are actively working on migrating our recall infrastructure from FAISS to pgvector. This migration will consolidate our recall mechanisms into a single document store and open new opportunities for optimizing recall.
By bringing together these strategic enhancements, we are committed to delivering a superior search experience for our users, helping them find what they need quickly and efficiently.
Stay tuned for our upcoming blog posts where we will dive deeper into our migration from FAISS to pgvector and share our continued advancements in hybrid search.
Acknowledgments
This project required the collaboration of multiple teams across the company including ML, ML infra, backend and core infra teams to be realized. Special thanks to Guanghua Shu, Xiao Xiao, Taesik Na, Alex Charlton, Xukai Tang and Akshay Nair who also contributed to this work and made this vision a reality.
Optimizing search relevance at Instacart using hybrid retrieval was originally published in tech-at-instacart on Medium, where people are continuing the conversation by highlighting and responding to this story.