Criteo
Research Card: Mode Identification with Partial Feedback
2024-9-12
Criteo R&D
An adaptive algorithm that learns the best sequence of questions to identify as quickly as possible (in terms of questions) the most probable label for data points.

- Paper: Mode Identification with Partial Feedback
- Authors: Vivien Cabannes (Meta), Charles Arnal (Univ. Paris Saclay), V. Perchet (Ensae & Criteo)
- Category: Annotation
- Revue: COLT 2024
Why did we work on this topic (the problem we want to solve)?
In a standard theoretical labeling problem (in order to learn a classifier), queries are either of the form: “What is the label of this unlabeled data point?” and the answer is the correct label, or: “Is the label of that data point a cat?” And the answer yes/no. Both approaches are more or less equivalent and relevant when the number of different classes (or potential labels) is small.
With a large number of different labels, maybe organized with some tree-like hierarchical structure, things are more complicated as querying for an exact label might be quite wasteful. For instance, if you want to identify the correct breed of a cat or a dog picture, you might want to ask first whether the label is “a breed of cat” or “a breed of dog” before testing all the breeds of cats (and finding out it was a dog).
Our objective is to design an adaptive algorithm that learns the best sequence of questions to identify as quickly as possible (in terms of questions) the most probable label for data points.
What did we find? What did we achieve?
We find an optimal adaptive algorithm that is based on some information-theoretic representation of probabilities, the so-called Huffman coding (a variant of the maybe more popular, but less adapted to this case, Shannon coding).
Combined with very precise online learning techniques, aka. bandits algorithms, we were able to prove the optimality of our algorithm, in the sense that the number of queries (or annotations) made to reach a given level of accuracy is much smaller than those of the current naïve approaches.
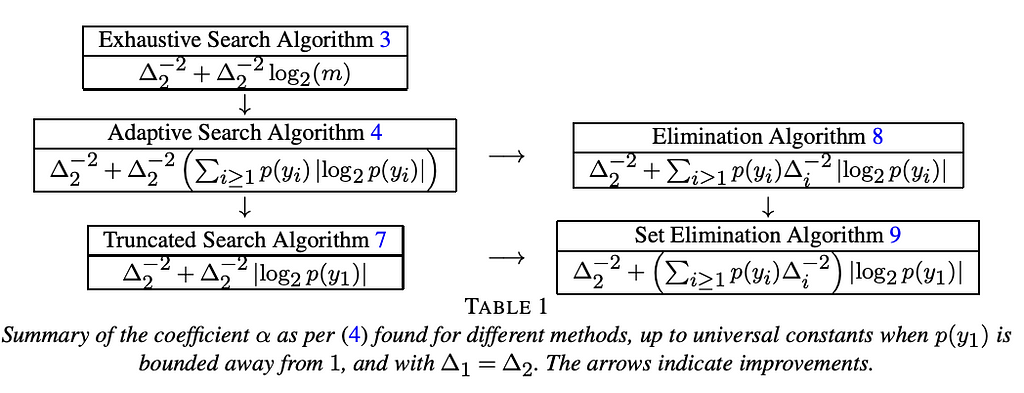
How did we proceed?
This work is essentially theoretical, but as usual, we do not want to take existing papers and move epsilon around. What we did is the opposite: I discussed with my co-authors of the criteo-original problem, that we modeled mathematically (by removing some assumption to simplify the analysis) and solved !
What is the originality here?
The originality is in the fact that labeling is not « label by label » but with a group of labels. This is rather obvious when you think about it, but the community had not investigated this yet. This mighe be because you need close collaboration with industries to understand what are the actual interesting problems.
Check all our research cards 👇
https://medium.com/criteo-engineering/research-cards/home
Research Card: Mode Identification with Partial Feedback was originally published in Criteo Tech Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.